Scaling tacit knowledge
Table of Contents
Nobel Prize winner P.B. Medawar once wrote, in Advice to a Young Scientist, that 'any scientist of any age who wants to make important discoveries must study important problems.' But what makes a problem "important"? And how do you know it when you see it? The answers don't come from reading them in a book, or even by explicitly being taught them. More often, they're conveyed by example, through the slow accretion of mumbled asides and grumbled curses, by smiles, frowns, and exclamations over years of a close working relationship between an established scientist and his or her protege. (Apprentice to Genius)
Ben Reinhardt posted earlier in October the picture below. It shows two ways to "learn a field": one is the "right one" (talking to people, the outer loop) and another is depicted as a misconception, where one just reads key papers. Learning a field can take multiple meanings, it can be learning the content of the field, learning the social context of the field (what are the active areas of research, key labs, its history), or learning to do research in the relevant field.
As someone who's an example of being in that inner loop, I thought it'd be worthwhile to engage with this, but over time that ended up growing into a longer and somewhat meandering essay on the nature of tacit knowledge. If you are left wondering what do I really mean, worry not: the conclusion has an enumeration of points I want to make. This essay makes a heavy use of examples and analogies, everything you need is linked from this essay, so you should probably be clicking in all the links! If you want the TLDR now, here it is: Expertise requires acquiring a degree of private and tacit knowledge. Expertise cannot be taught using only explanations. Acquiring expertise can be accelerated by means of being exposed to a large library of examples with context. We are not leveraging this as much as we can and we should experiment more to explore how far this method can get us. What I describe in this post is a hypothesis that is looking to be tested and I offer indirect evidence for why it may work.
Ben is not the only one with a person-first approach to learning: In the same Twitter thread, Alexey Guzey joins Ben with a 90/10 split between talking to people and reading. This is not due to some limitation with the written vs verbal form. There are some people out there like Rob Wiblin that find it hard to read anything at all. Ben and Alexey's point is very different: Is there knowledge that can only be gained by talking to the experts? Is it faster to gain certain kinds of knowledge by talking to the experts?
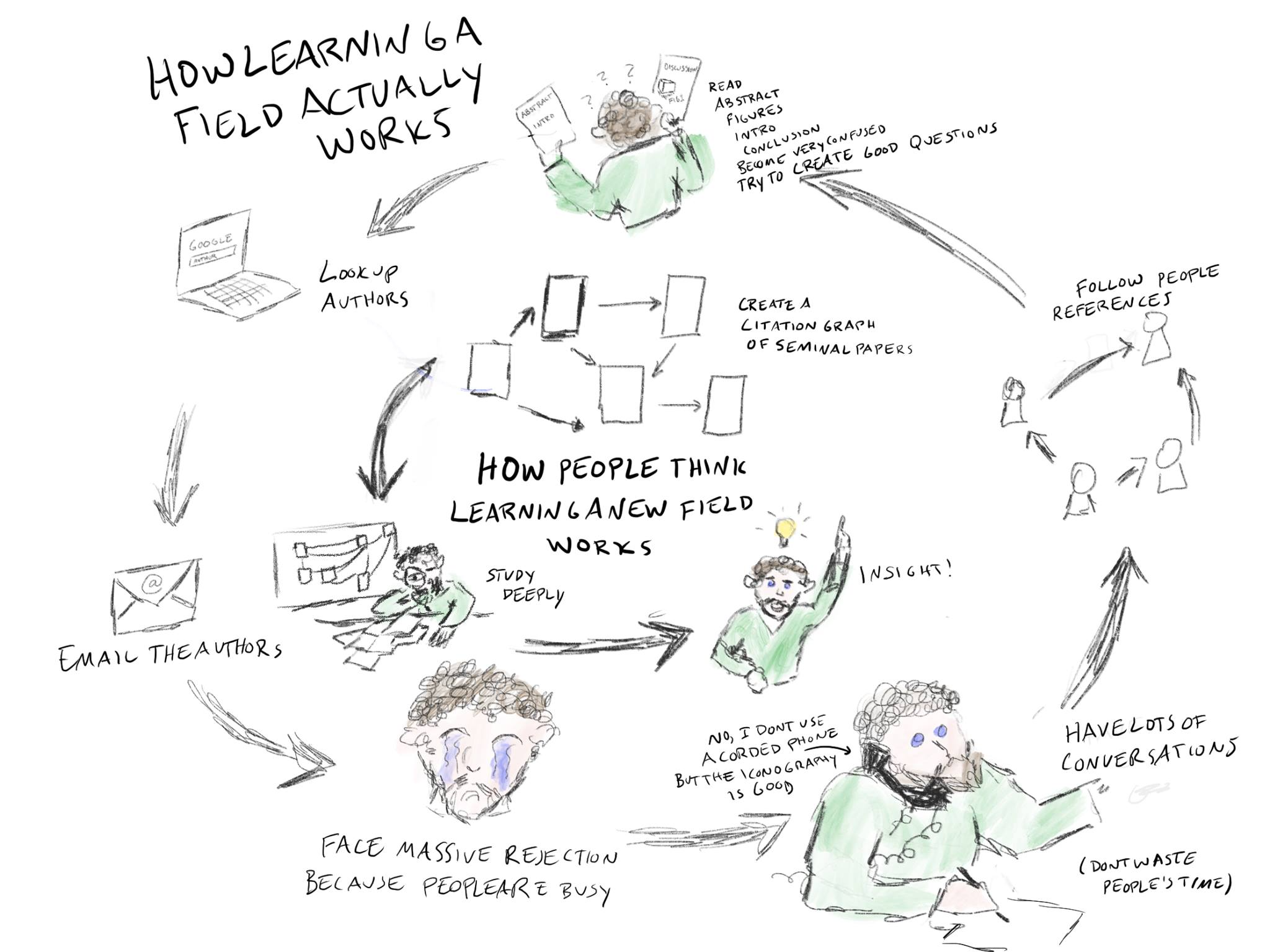
To be sure, I don't only read papers, nor does Ben exclusively talk to researchers (There's a "reading papers" Ben at the top of the picture). Reading papers and talking to people are clearly both useful.
Why would one talk to people instead of just reading? Reading has the advantage of input speed: I don't know anyone that can speak faster than I can read. Reading also has the advantage of being able to incorporate figures, links, tables, or citations. And even better: One can jump and skip ahead in text, have multiple documents open at once, go back and forth and traverse more knowledge than a single person can possibly have in their head, zoom deeply into the specifics of one given paper, find related and novel work. It's hard to do this within the time box of a video call or an in person meeting.
However, the reading-first approach means that at first one will take a very long time to get to answer a question that would just take seconds to ask an expert. For example, if one just wants the answer to "Does rapamycin extend lifespan in mice?", getting to understand the relevant literature can take months. Sure one could do a quick Google Scholar (or plain Google) search and find a bunch of papers, but that comes with some built in confidence level (How sure are you that the papers you found are good?). A quick call with an expert can just give you the answer, the rationale for the answer, debates around the answer (Does it work in some mice but not others? Will it work in humans?), considerations or assumptions that you had not initially considered (The idea of compounds analog to rapamycin (rapalogs), that the answer may differ by dosing schedule) and so forth. You can't interrogate a paper, but you can ask questions to an expert (As Ben put it, in conversation).
This one-off interaction with the expert also comes with its own built in uncertainty: Was the expert chosen correctly? Do they have their own biases that should be factored in? What if multiple experts contradict each other? This interaction wouldn't lead you to learn a field, just to gain a small piece of knowledge about one molecule, rapamycin. For this one particular case, it seems to me the heuristic "Check on the internet for 10 minutes and find an answer, otherwise call the expert" would work, but it would work only if one has some prior background to quickly find and aggregate research work.
Here's a more complex example: Suppose you want to learn how much salt you should be taking. The Google approach yields 2.3g per day (FDA guidelines). But then you are of course smarter than this and you keep digging; you deploy the heuristic of inverting common knowledge (more salt is worse, period) and try to find evidence that actually, too little salt can be bad. You come across some work on that, showing that there's a U-shaped relation and that perhaps the right amount of salt to consume is more than the guidelines say. You feel smug and smart. You talk to some doctors that vaguely gesture at the U/J-shaped relation between salt and mortality. But some time after, you learn of a piping hot meta-analysis fresh off the press, analyzed and endorsed by this one Stephan J. Guyenet on Twitter, reasserting accepted knowledge: less salt is better. This is the answer I would believe, but for this particular one, I started with an advantage because I have done the prior work of searching experts to trust in that one space (As it happens, my other go-to expert for nutrition matters concurs with Guyenet). Whether here one ends up with the correct answer or not would depend on how good one is at interpreting primary sources and how good one is at finding good experts. But here we don't have to talk to the experts, for this one very simple question that asks a relation between two variables, we can rely on short analyses from the experts; this both points to primary sources and explains where the contradictions may be coming from. This is better in one regard than talking to the experts; they probably can't cite all these papers from memory, nor immediately address what the trouble is with the discordant paper you found that morning. Particularly illustrative was this podcast between Gary Taubes (Who subscribes to the "carbs are bad" view) and Guyenet (Who think carbs are fine in moderation). Guyenet came prepared with a list of arguments and relevant work he could point to where he had pre-answered potential counterarguments to his views. Imagine now trying to talk to either of them vs reading their writings, or writing a best evidence synthesis of what they are saying. It seems obvious reading will yield the superior understanding, but not necessarily a better answer and definately it will take longer.
But these two topics are still very simple and by no means get anywhere close to "learning a field", they are about very specific questions. If instead we want to know what are open questions in the field? Or, what would be projects that could accelerate the field, or something of that sort? Those links do not yield good answers. There is no trivial googling that will in general get you answers there so one can't use the shortcut of finding expert analyses. One truly has to get the field, and doing this can require acquiring forms of knowledge that are harder to find out there by reading papers.
Tacit knowledge
What tacit knowledge means differs by whom you ask, but in general the definition refers to knowledge that is very hard to acquire (In the broadest definition) or knowledge that is embodied in a person (or group) and that they can't make fully explicit. Of importance here is that talking to an expert wouldn't get you that knowledge, in this second definition. An obvious example is riding a bike; one could read books about cycling or talk to Tour de France winners for months and not have much idea how to skillfully ride a bike on a first trial. Tacit knowledge may be hard or impossible to get from experts, but this is not that bad: one doesn't need this tacit knowledge for many purposes. If all you need is a precise answer to a question, asking a panel of experts (if they agree on the answer, at least) can yield a reasonably trustworthy answer even if we are not fully aware of the chains of reasoning and specific pieces of evidence the experts are relying on when delivering that judgement.
Experts are worth talking to for reasons other than them having tacit knowledge: in the example earlier the expert may know the right answer to the rapamycin effectiveness question, but this piece of knowledge happens to be publicly available (a form of explicit public knowledge). Experts also possess private explicit knowledge which can be important and is what one mostly gets from one-off calls from experts. They could tell you that "That paper that seems promising from 30 years ago? Yeah, a friend was there and it's quite sketchy, anyone you talk to from that lab will confirm".
In an ideal world, one would learn this from reading about later attempts at, say, replicating or extending that line of work, but we don't always live in that world. This kind of knowledge is different from tacit knowledge in its purest form in that once we gain that knowledge, we could make it public and anyone could effortlessly learn it without having to talk to the expert again. Systems like Pubpeer try to scale this sort of knowledge by providing a centralized repository for commentary (generally critiques) of scientific work.
Here's a brief typology of the knowledge relevant for the purposes of this essay. The lenses that are driving these categories are two: First, can we scale the knowledge without having access to a tutor, and second, can an expert even teach you without them being present.
- Explicit knowledge
- Public
- Private
- Tacit knowledge
- Public
- Motor skills
- Intellectual skills
- Private
- Social
- Individual
- Public
Explicit knowledge
Public
These are facts that are easy to come by and not particularly worth saying much about. "What's the capital of the United Kingdom" or "What's the market capitalization of Tesla as of today" can be quickly looked up on the internet.
A problem with public explicit knowledge is that there is a lot of it, and interesting chunks of it are not trivial to interpret. As in the example of the salt and mortality correlation earlier, there is no general oracle that will spit out facts that are guaranteed to be true. Interpreting available public knowledge, and knowing where to find it in the first place, in some situations requires nontrivial amounts of other kinds of knowledge, some of it tacit.
Private
Some knowledge is not particularly hard to transmit if someone wanted to but they may not have incentives to do so, and so it remains private. For example, when designing a scientific experiment it may be useful to know the cost of various reagents, supplies, and equipment. Many of these prices are available online. But others are not, hidden behind a "talk to sales" button or an email to the right person. If one is in the relevant social circle, a quick message to a colleague can get you that information. This knowledge could be made public, but generally there are incentive problems why this is not the case. In the pricing example, vendors may make buyers sign NDAs to avoid leakage of the pricing information.
Tacit knowledge
Harry Collins and Robert Evans, in their Rethinking Expertise define tacit knowledge as the deep understanding one can only gain through social immersion in groups who possess it. This is one possible definition, but to my purposes here, an overly narrow one. Tacit knowledge in the Collins-Evans sense will correspond to what I call here private individual tacit knowledge. Note that "groups" could be a single person (as in a master-apprentice relation).
Public
The first type of tacit knowledge is one I'll call public to mean that one could acquire the skills with publicly available information, without need of a coach, tutor, or apprenticeship.
I divide this set of skills into two: motor and intellectual. In practice this distinction is not clear cut, but broadly for "motor" think riding a bike and for intellectual think activities that all look like sitting at a computer typing away. An example of a hybrid is instrument-playing; playing an instrument requires some very fine motor skills but also some sense of what good music sounds like. One can hire a teacher to learn how to play, but anecdotally many famous guitar players are self-taught.
Motor skills
There's a type of tacit knowledge where you need to do something (as opposed to reading about it or talking to an expert about it) to gain the skill. A bike theoretician that has spent a year reading about bike riding and videocalling with bike pros can't hope to ride a bike proficiently, if at all, on a first trial. At the same time, one can learn to ride a bike alone. If you watch this video, you can see a sequence of steps that would orient you in the right direction. You still need to ride a bike and practice, but the video has enough guiding to learn the skill.
But this kind of knowledge (the one involving novel movements or fine motor coordination) is not the kind of knowledge relevant to most knowledge work, the focus of this essay.
Intellectual skills
One example of this is judging the doneness of a particular item being cooked (could be a steak or a quiche). Someone that has cooked it a lot could tell when it is ready, but if asked to explain it, she could point to the appearence of some brownish patches, but not too many, or there being such and such smell. But despite not being able to verbalize this knowledge, we can still teach it to some degree, in this case, in video format. Watching someone cooking the item repeatedly can give a sense of what "done" means. This is a trivial example of how tacit knowledge can still be scaled, despite the expert not being able to verbalize it. It also points to a key factor in enabling scalable tacit knowledge: Whether there are external artifacts that we can observe. A video of someone meditating wouldn't teach much about how to meditate.
Skills that fit here would be chess (Where we have external artifacts, the chess board) or writing (Where the output can be read).
Private
This is the kind of knowledge that could only be acquired by means of an apprenticeship and/or being deeply embedded in a community of practice. It requires someone to transmit that knowledge. The fact that it is private need not be an intrinsic feature, as with explicit private knowledge. But supposing we could overcome these incentives issues and actually get to sit down with multiple experts, could we make private tacit knowledge into a form that is amenable to individual learning, and thus scaling? This is one of the core driving questions of this essay, but getting there will require some meandering through examples.
Individual
This is the class of knowledge Collins and Evans have in mind in their definition earlier; for this it's not enough to apprentice, you need to be embedded in the relevant community. Individual private tacit knowledge is the one that you can gain as an apprentice. An example that comes to mind is learning how to design glass sculptures in the style of a particular niche artist that is not recorded in video.
Social
This is the knowledge that somehow would be embodied not in the nodes but in the edges of a network of knowledge workers. It's different from the other categories in that the knowledge is not in anyone's head (so no apprenticeship will get you there) but it's embodied in an entire organization. As an example, I will claim the CEO of TSMC does not know how TSMC works. Nor does anyone know exactly the entire chain of processes that lead to the production of a humble pencil. But somehow the economy as a whole does. As with motor skills, this class of knowledge is outside of the scope of this essay.
I want to close off this section with a brief discussion of an example that illustrates an example of social tacit knowledge, how hard it can be to reconstruct, and how we tend to see these sort of examples.
Fogbank
Suppose you hire an army of smart physics PhDs that have zero knowledge of how to build nuclear weapons, then ask them to design one. Could they do that? In a recent post from Rohit Krishnan the answer from a real world experiment is apparently yes and to the extent one distrusts that one report, I think some trial and error of their own (they were not building the device, just designing it) would have set them in the right trajectory. But Rohit also notes there the case of Fogbank, where trying to manufacture a material used in atomic weapon manufacturing that was last made decades prior, took many years and millions of dollars to recreate, despite having access to the original instructions for how to make it, and despite being able to talk to those that worked on the project originally. Turned out some impurity being added was key, and no one in the original team was aware of this! This is interestingly very similar to Collins (2001), where US-based researchers tried to replicate Soviet measurements of a parameter of sapphire samples, unsuccessfully. Turned out that the key to take the measurements in a comparable way was to
The second method of greasing thread demonstrated by Checkhov, and used interchangeably with the first method, was direct greasing of the fine thread with human body grease. Checkhov would run the fine Chinese thread briefly across the bridge of his nose or behind his ear. The ear method was adopted by the Glasgow group, though it turned outthat only some people had the right kind of skin. Some, it transpired, had very effective and reliable grease, others’ grease worked only sporadically, and some experimenters’ skins were too dry to work at all. All this was discovered by trial and error, and made for unusual laboratory notebook entries such as: ‘Suspension 3: Fred-greased Russian thread; Suspension 12: switched from George-grease back to Fred-grease’, and so forth. As with James Joule’s famous measurement of the mechanical equivalent of heat,”! it seems that the experimenter’s body could be a crucial variable.
The Sapphire example is referenced elsewhere; Ben's notes and most discussions of the paper focus on the central point of the paper: the need for personal interactions and trust to effectively convey tacit knowledge. But the conclusion of the paper is almost as important: Collins suggests a way forward! Instead of resigning ourselves to lenghty and costly trial and error we could do better:
Reporting a Second Order Measure of Skill: This kind of science could be made easier if the importance of knowing the difficulty of an experimental skill or procedure was recognized and emphasized. The conventional style of writing scientific journal papers (and even books) excludes details of this kind. Yet someone trying to rediscover how to produce a result in the absence of a laboratory visit could be helped by knowing just how hard the experiment or measurement was to carry out in the first place, and just how hard it continues to be. Such information could be roughly quantified — it is a ‘second order measure of skill’.*° Experimenters could record something along theselines:
It took us some 17 months to accomplish this result in the first instance, during which time wetried around 165 runswith different set-ups, each run taking around a day to complete. Most successful measurements on new samples are now obtained in around 7 runs, butthere is a range of approximately 1 to 13 runs; each run now takes about 2 hours. The distribution of numbers of runs on the last 10 samples we have measured is shown in the following diagram ...
Information of this sort could be expressed briefly, without radically changing the conventional style of scientific paper-writing, and yet could be of significant benefit to those trying to repeat the work.It is just a matter of admitting that most things that seem easy now were very hard to do first time round, and that some remain hard even for the experienced experimenter. We concede, of course, that within the current conventions of scientific writing, setting out these difficulties would look like weakness; science is conventionally described as though it were effortless, and the accepted scientific demeanour reinforces this impression. What we are suggesting is a slight transformation of convention and demeanour—with a view to improving the transmission of scientific knowledge.
This is just one way to enhance scientific writing for ease of reproducibility, but one could think of others.
The same is true of discussions of Fogbank: The core lesson is acknowledged (Tacit knowledge is real, and hard to transmit!) but such acknowledgement is so strong that hard is made to seem impossible, so no solutions to the problem of tacit knowledge transmission are proposed. We should not look at tacit knowledge in awe of its fractal richness, being humbled by its existence. Rather we should look at tacit knowledge as a challenge to be overcomed!
Some examples
Tacit (and private) knowledge in the life sciences: the Rejuvenome
One can get a textbook on molecular biology and read it, yielding knowledge of various facts about molecular biology. Does then one become a molecular biologist? No, because the knowledge required to do that is of a different sort.
This is clear with a brief example: Suppose somehow a copy of A single combination gene therapy treats multiple age-related diseases (2019) lands in your desk. You read it. Assuming you remember what is literally written in the paper you will be able to answer questions like:
- Who authored the paper?
- What genes were delivered? (FGF21, Klotho, sTGFbR2)
- How were they delivered? (AAVs, one with each gene)
- What was one test that showed effective treatment of a disease? (improved glucose response)
There is a second kind of questions that you could be able to answer if you have read many papers of this sort that you won't be able to answer if you only read this one paper:
- What other ways are there of delivering these genes?
- Are the tests they are using "good"? Do they support their claims?
Now even if you understood perfectly well the context of this paper, and were able to discuss it passing for an actual expert in the field, if you wanted to repeat the experiment they did, by yourself, without any help, would you be able to? In exactly the same way the authors did? Probably not, and this becomes more clear the more you try to design the actual study. For example, you need to feed the mice something, but the study doesn't say what the control group gets other than it's a "normal diet", so you need to assume one. This is also a case where you could ask the authors (The answer: Normal diet means something like NIH-31). Then, would you be able to inject the viruses in the way described in the paper (retroorbital injection) without prior training? And what anesthesia would you use (the paper doesn't say; is isoflurane good?). For qPCR, what temperatures and timings would you use (the paper doesn't say).
There is something you wouldn't get in any way other than asking the authors: Why is the study the way it is? Why those three genes? And why did they test the things they test?1
There is a hierarchy of knowledge at work here:
- Learning core facts (What's on the abstract and conclusion)
- Learning how facts relate to each other (e.g. what subfields are in a field, what alternatives are there to a particular choice, where does this piece of work fit in the field)
- Learning how the knowledge was generated in the first place, all the way down to specific pieces of equipment (The methods section and beyond)
- Learning to design novel experiments
The last one is the hardest one to make fully explicit because by then you're dealing with the frontiers of knowledge where the "facts" to rely on are not so much published results and more like hearsay from someone that tried this or that in their lab, and some .csv files you are sent from data pre-publication along words of caution not to further share it.
Here's a concrete example of 4: When designing the Rejuvenome project (That ultimately ended up being hosted at the Astera Institute), one of the design considerations was to have genetically heterogeneous mice. Usually lab mice are inbred, they are crossed sibling-to-sibling for generations until the resulting population is isogenic. Why do this? The textbook rationale is that if the genetic background is the same then that can reduce the variance of the experiment, leaving only experimental conditions, which can be controlled as well. However, this can also lead to a given therapy working only in one particular kind of mouse, but not others, making the results less robust. Maybe the mouse tends to develop a particular kind of cancer very fast and therapies that target that will show outsized increases in lifespan that will not generalize. This kind of reasoning is why the gold standard for intervention effectiveness in the aging field, the Interventions Testing Program uses genetically heterogeneous mice known as UM-HET3. These mice have drawbacks: You have to (at the time) breed them yourself, then wait 18 months to age them. Based on this reasoning and the fact that they were good enough for the ITP, those were the mice that went into the original Rejuvenome draft. At that stage, I had no idea of how they would be housed (Answer: ~5 a cage) or what they would be fed (Answer: this), but I knew the ITP was running a similar program so those answers must exist somewhere. These particulars therefore, were left as "mere" implementation details that would be elucidated later, but which didn't affect the high level design of the study.
After that initial stage however, we learned some new things that were not obvious from just reading papers, this time from talking to researchers in the field:
- That some, believe the "isogenic=less variable" argument is actually false, on the grounds that isogenicity makes the mice weaker and couples them more to the environment (if an effect=genes+environment+interaction, this latter term would go up), amplifying that noise. This view is not universally shared.
- That there are other kinds of outbred mice, like the Diversity Outbred (DO). That naturally leads to the question of whether to use those
- Some time after that, we learned that DO male mice are very jumpy and aggressive. Given that we knew that for females you could have 5 in a cage, what happens if the males have to be single housed? Should we just do the more peaceful HET3s?
- Some researchers opted instead for studying only female mice. The papers using these all-female DO cohorts wouldn't explain why it was only females. In retrospective that was because of an undisclosed fact (That the authors told us, but did not write down: That they thought the male DOs would be too aggressive)
- We had lifespan data for the HET3s that's publicly available but not so for the DOs. We only got that by asking around and we were sent a .csv file with data from an upcoming study. Lifespan data is important to do some statistical calculations regarding sample size and power.
- We wanted to do all sorts of "omics" on the blood. But how much blood does each of these methods require? How much blood is in a mouse anyway? (1.7-2.4mL) How often can one get this blood? (Once a month) This is not so much tacit knowledge, all this information is publicly available and there are guides and even videos of how one would go about doing it. But initially these seemingly minor details were not in our mind which meant that very concrete questions like how many mice get sampled how often, or whether the same mice would be sampled throughout the study or even whether samples would be pooled were not considered. And some of these affect the study design!
- Altos! Altos Labs was one of the big reveals of the year in the field. But in the field people had been talking about it for months prior, in various online seminars and Q&As one could hear references to a new "Milky Way Foundation" launched by "some" billionaire. PIs here and there would mention that they had gotten a grant from them. This kind of knowledge is not so much about the domain the field studies (aging) but about the field itself and definitely impossible to acquire just by reading papers. Probably also impossible to acquire by trying to talk to researchers unless you were deep enough in the field for the other party to assume that you are already in the know.
- A certain promising study in a subfield of aging that showed substantial lifespan gains was not fully accepted as generalizable because it used progeroid ("fast-aging") mice, so there was the possibility that the intervention wouldn't work in regular mice. Many in the field when asked wished to know what would happen if it were repeated in regular mice. I had coffee with a scientist in the field who mentioned to me (While discussing unrelated matters) that the study had been done (along with the results) and that would be released eventually. This knowledge would make one be slightly less bullish on said intervention, which has implications for study design: We had planned to actually do that study ourselves as part of Rejuvenome, but now we can use that prior art to decide whether to improve upon it.
Most of these pieces of knowledge are actually explicit private knowledge, not tacit knowledge, but in practice the borders between both are blurry. Yes, in theory the answers to all the questions one wants to ask about study design are in someone's head and they could tell you if you asked. But you don't know what questions to ask. Knowing what the right questions to ask is a form of tacit knowlege. A novice in study design (i.e. me, at first), when hearing "We're going to do X,Y,Z things with blood" would probably just nod. An expert would probably ask how much blood each assay requires perhaps because X,Y,Z sound like too much. It's not like the expert had to think about that objection, it's that the relevant questions to ask become more salient with expertise.
Going back to what I said earlier about the Diversity Outbred being aggressive, you can get from here that they can be jumpy and the males can be very aggressive. The jumpiness point can be learned from other public sources. That males are aggressive and necessitate single housing (Usually you can have say 5 mice in one cage) was something that as a matter of fact could have been learned from public sources but it wasn't, it took someone to tell us that this specific issue was relevant.
However! Even after these and many other findings, the latest iteration of Rejuvenome still looks very similar to the original vision and overall the tacit knowledge I've gained has played more of a finetuning role rather than informing the core vision of the study.
Tacit knowledge in meetings
Meetings are universally hated and rarely loved. Running effective meetings is a form of tacit knowledge. There are for sure principles that can be distilled but I don't think just stating them would be very useful. For example, consider someone that suggests having an agenda for a meeting. If one just gets that suggestion one may be tempted to think why do that, we can just wing it as we go. One can add have an agenda, because otherwise you won't cover the topics you want, you'll drift and reprioritizing during the meeting is harder. But even then one could think I'm smarter than that, can still do it. Situations like this one abound in other domains on life. Does one need to fail to really understand why some norms and frameworks exist?
Conversely, when one accepts as obvious the idea that if a meeting is going in circles one should do something to stop that, knowing that in the abstract doesn't mean one will do it. At least in my own experience, I've been in meetings where the loopiness was only seen after the fact. In later meetings loopiness can be picked up by a sense of distress ("Something is off with this meeting"), a sense of impatience ("I've heard this before") and a sense of doubt ("Are we repeating ourselves?... or maybe they are just clarifying what they said"). Eventually when one should or should not voice that the group is running in circles (vs clarifying and weighing various options, incrementally adding) becomes clearer and clearer. Eventually one ends up thinking of ways to avoid getting there, studying why those frustrating conversations happen in the first place, leading up to say what I describe here. There's nothing new I can add to how to run effective meetings (Though I could write a post on that summarizing what I know). But when thinking about them I've ended up thinking that when giving advice it's important in many cases to explain where the advice is coming from, and at the receiving end being humble enough to override your rational judgement ("I know better; I don't see why I am wrong") and follow a principle instead ("Experts tend to be right in this context")2 .
Tacit knowledge in reference checks
Ok I cheated there is a third one, but this one is brief. Investor Graham Duncan (profiled here) has an article, What's going on here, with this human on hiring, with a strong empasis on obtaining references. At the bottom of the essay, Graham gives us a guide to do references, questions to ask, and a guide to do interviews. That's the explicit knowledge that the author tries to use to capture what is going on in his head. Reading the essay (And Commoncog's profile) changed my mind on the idea of obtaining references. Whereas before I would think that "Why get references, they are going to be biased" now I think that "There is going to be some truth mixed with the potential bias, but if one asks the right questions one can get to some of that truth. By asking multiple people the right questions, one can triangulate how the person really is.". But I still do not know how to do Duncan-level reference checks!
Tacit knowledge in scientific literatures broadly
There is more knowledge in science than is written down in the whole of published papers in a given field. But at the same time, there is more knowledge embodied in a set of papers than is written down in the papers. If you read this tweet maybe you can relate to that phenomenon, you can read a paper and get what it means while acknowledging (from past experience) that such understanding is very thin. Last year I wrote a post on understanding biology where I try to explain the process that takes you from that to a richer understanding. If you read enough papers you end up noticing things that the papers are not saying; this can be how often certain entities are mentioned, which labs tend to publish what kind of work, what methods are more frequent, whether a given paper is being thorough or not (by comparison to others), or even whether a given result is a priori trustworthy (e.g. is this an area where contradictory results abound or no matter how you measure you get the same thing). Reading research literatures is like an example I'll discuss below (language learning). One is constructing a model of the domain by using the papers as pieces of data. The task is not to memorize the specific papers (after all they can be wrong) but to build a model from which the papers become predictable. A trivial example is if a paper claims an association between A and B and another between B and C, nowhere in the literature says that A could lead to C, but if one is aware of A->B and B->C one could infer A->C and then try to look for evidence of that relation.
Sharing tacit knowledge
Tacit knowledge cannot be taught verbally, or written down. It can be distilled in various ways, and hinted at, but that's it. This doesn't mean we are doomed to lose that knowledge once the expert dies: tacit knowledge still can be acquired. The issue is that not everything that can be taught can be explained. The expert can introspect and derive some rules and principles that try to capture the depth of their knowledge, but that is not the knowledge itself. This is why one can read books by people that clearly knew what they were doing and yet not be able to get anywhere near the performance of said experts.
But surely there is somewhere in the middle between asking experts to write down what they know (and fail at it) and apprenticing with the expert. What would it take to accelerate learning of a domain, and facilitate diffusion of the knowledge embedded in it? I think that the answer is being exposed to a library of expert performances (or examples) in context. Rather than asking the expert to write down how to do great job interviews, watch a few dozen hours of the expert doing interviews. The expert wouldn't be explaining how to interview, he would be doing the actual task. This seems a close proxy for the apprenticeship version of this, sitting next to the expert. The video probably captures most of what is relevant. Software engineering could be taught to proficiency similarly. The same is true, I reckon, for scientific skills (study design, literature evaluation, problem finding) if one added some running commentary.
This approach to learning is not new, despite it seeming unusual: This is how language learning works!
Language learning
As various personal reports scattered through the internet show (e.g. this), one can learn a language from a basement in complete social isolation from the community of speakers of said language, without ever talking to other human being in the target language. We also know that being thrown into a foreign country and forced to interact with such an environment can greatly accelerate language learning. Anecdotally, when I visited Japan some time ago I kept seeing "出口" near exits, so I started associating that to the concept of exit. I didn't try consciously to make that association, it effortlessly emerged from seeing it all the time.
The interesting thing of language learning is how effortless it seems to be for children. The conjunction of massive input of examples with the right context leads initially to remember salient words first, then noticing overall patterns, inferring grammar, and ultimately speaking the language proficiently. Adults can learn languages in the same way in about a year by the same means: exposure to a large library of examples with the right context. In one case, 18 months was enough for this one person to go from zero to near-native proficiency in Japanese.
I am not claiming we can learn everything using the same mental structures we use for language. Perhaps language is easier than other domains because we are pre-wired for language acquisition in a way we are not for other domains. I am saying that there is a domain where this (massive input of examples with context) obviously works and we should think about seeing if we can expand that to other domains.
The fractal complexity of tacit knowledge: Polymerase Chain Reaction
Here's something that is at first conceptually simple but then happens to be quite complicated: for context read this essay from David Chapman on PCR. There are many videos and resources online that I perused writing this section and the full complexity of what doing and understanding PCR actually entails is not obvious at first.
Polymerase Chain Reaction is a technique in biology to do amplify fragments of a specific sequence of DNA. Could one learn how to do PCR just by reading about it? Maybe. Even if not impossible, we'd agree it would be hard, for the reasons explained in Chapman's essay. One could then supplement text with video: Watching someone actually perform PCR seems to be a substantially better way to learn how to do it. Even better: watching someone fail at it, and explain what went wrong, and how to fix things along the way. Even then, I wouldn't suspect one would get it right on Trial 1, but you could probably get better at it. With the videos and written materials, and clear examples of what success looks like, you could get there. I don't think this is easy, because to do PCR if one has never been in a lab entails a range of accessory knowledge and skills that have to be gained first.
The video in Chapman's essay starts with "the first reagent we will use is buffer" and then he continues. To someone that has never done PCR, the nature of this buffer is unclear. The "real world" explanation is that this buffer is "10X PCR buffer" and this usually comes with Taq polymerase (The enzyme that copies the DNA) if one buys it from e.g. ThermoFisher. In turn, that's buffer from ThermoFisher is mixture of HCl and KCl. And this is a buffer in the sense that it keeps pH constant when adding a small amount of a strong acid or base. In turn this is required because the polymerase used works best at a certain pH. Said polymerase also requires magnesium but ThermoFisher in this case includes it separately from the buffer, leaving it up to you to decide how much you want: too much and the results will be noisy, too little and there won't be enough amplification of the DNA. Why does Mg do this? One could indeed keep going deeper and deeper; moreover stabilizing pH is not the only reason why KCl is there; nor that is the only kind of buffer that can be used. For a user of PCR, this doesn't matter: One only needs to know that there's a tube with buffer that comes with the polymerase one buys. It of course matters if one wants to improve PCR protocols. In Lorenz (2012) for example a case is described (In Section 13) of trying to find the right concentration of magnesium chloride to amplify a particular gene. The concentration suggested by the manufacturer did not work, but current state of the art is to just try a number of concentrations. In practice, if one works at a particular lab, at first one doesn't know all of this, all you need to know is that there's a bottle with buffer and another with the polymerase. That complexity is abstracted away. Initially perhaps you have someone who knows how it's done giving you instructions and you walk through it, mistakes are made and corrections are issued until one has thoughtlessly performed the process. But then one may be able to do it on ones own, then do it for different DNA fragments and so on until one can claim to know how to do it.
Something of interest in that same section of the Lorenz paper is that the authors deliberately do PCR wrong to see what happens; if one thinks of learning a task as there being a core domain and some fuzzy edges, learning these borders of the task are important as well: the borders are where the task starts and ends (Where do you get the materials to do the task, what do you do once you are done?) but also where one can be forced out of the task: If you do one step wrong or if something doesn't go according to plan, what does one do? If all one has done is the textbook case then mistakes can lead to paralysis or starting from scratch instead of an appropriate fix and continuation of the task.
PCR involves many subskills that are left implicit in the instructional material. The protocols involve using micropipettes to dose the right amounts of various reagents into a little PCR tube. Using one such pipette is a relatively simpler task, but one that must be learned as well (We could further decompose the task in changing the tips of the pipette, learning to read the volume counter in various types of pipettes, changing the volume, and doing the pipetting itself). Others include operating a thermal cycler, and if one further expands the scope of the task then we have others: primer design, knowledge of how to order all the required equipment and reagents, and so forth.
Is that enough? Not quite! One can keep going on about PCR: This other walkthrough of PCR mentions that if the DNA sequence is GC-rich you want to increase the time of the denaturing step but one can also achieve the same by increasing the temperature. Temperature which also depends on the melting point of the primers being used; and time which depends on how long the product to be obtained is, as well as the polymerase used. The primers being used are not fully dictated by the sequence of interest, one has to design them carefully. An expert who has done this many times may eventually be able to guess what the right temperatures are from past experience, or have a feel for what a good answer should look like.
Reading about PCR "in the abstract", watching the PCR videos linked above brings to awareness the fact that all of that ends up being quite useless if one wanted to actually do PCR from scratch to, say, see if there's COVID in a sample. Suppose instead you had a series of step-by-step case studies with different primers, polymerases, and thermal cycles. Then you work through them like you would a new recipe. At first you are just mechanically running through a list of instructions. Eventually a sense of understanding should come in, knowing why each step is there, and how different it could be.
Chess, a domain where we have solved tacit knowledge transfer
Chess is an interesting domain to study tacit knowledge. The rules of chess are publicly available and can be easily learned. We have had centuries to develop chess-learning systems and frameworks. We have solved chess by means of ML. But getting good still takes many years. And good chess playing is definitely tacit knowledge: 100h of Magnus Carlsen talking to you wouldn't be enough to get you to play good chess.
A theme running through the sections above is accelerated learning: Is there any amount of training that will get you to Magnus Carlsen levels of chess playing in a few months? After some searching, I don't think so. The why is a combination of innate skill and the limits of human brains in acquiring the kind of skill that chess requires (chunking and planning ahead).
Chess skill is to a nontrivial extent heritable, to set our expectations. From my review on learning:
What about chess? Are Grandmasters good because they practice or because they were born with skills that are well suited for chess? At least for the case of intelligence, the correlation doesn't seem to go beyond r=0.35 in a meta-analysis of amateur and skilled players with ELOs between 1311 and 2607 (Burgoyne et al., 2016), this implies a variance explained (R^2) of around 6%. If we look only at professionals, the correlation is smaller, 0.14 This does not mean the other 94% is explained by practice. Indeed, if we look at heritability more broadly, for chess skill it may be around 48% (Vinkhuyzen et al., 2009 ) .
What's the impact, then, of deliberate practice? There is one paper (Burgoyne & Nye, 2019) that looks at it in a sample of moderately to highly skilled chess players (ELOs between 1150 to 2650) and we get that it accounts for 34%. Note that this doesn't mean that deliberate practice doesn't matter for novices! Indeed, for novices practice is almost all there is. Higher intelligence or better memory may give players the ability to better evaluate a board, but practice gives players the ability to do a such evaluations to begin with! It is only when one has moved past the novice stage when the effects from innate skills will begin to appear.
I tried to look for examples of getting good at chess fast and I found Max Deutsch's creative attempt, back in 2017, to become a chess grandmaster in a month. He failed, but did so an interesting way: initially he thought he'd do the obvious thing and learn from chess books, play lots of games, etc. However, that wouldn't get you to expert performance because
chess expertise is mostly a function of the expert’s ability to identify, often at a glance, a huge corpus of chess positions and recall or derive the best move in each of these positions.
Thus, if I choose to train in traditional way, I would essentially need to find some magical way to learn and internalize as many chess positions as Magnus has in his over 20 years of playing chess. And this is why this month’s challenge seems a bit far-fetched.
But what he did instead is quite surprising: instead of slowly absorbing a feel for the game, he tried to bruteforce the process by training a neural network that would predict which move to play next, then memorise the weights of said network and run it in his head. Or that was the plan, at least. That also failed (There are only so many weights one can fit in memory, and only so many operations one can do per second). He got to play with Magnus Carlsen (and lose) though.
We never got to learn how much Deutsch actually improved. There is data for chess grandmasters and what their Elo rating was at every given age. They all seem to learn at similar rates, at perhaps 40-50 points per year, but note also that they were amazing players even by age 15! The learning curve for Praggnanandhaa, which starts before he was 10, at a more reasonable (but still impressive!) 1500 Elo, improved at perhaps 200 per year. The fact that they all improve in similar ways should not be that surprising given that we have had decades if not centuries of thinking around how to learn chess and they are all probably using similar methods. This reddit thread suggests that maybe that 200 Elo per year increase is not that unusual when one is starting, so what distinguishes these grandmasters is not so much that they learn fast, but that they are gifted.
But there are also examples of faster learning: this random online person got from 1200 to 1600 in 6 months, improving 150 points in just 2 weeks at one point. Reading his notes, the pattern seems to be working through a library of examples (chess puzzles) of increasing difficulty, and memorizing games played by grandmasters. Attempts at memorization forces the development of strategies to enable that memorization, so just reading chess books or watching videos won't do it:
I would have considered it a waste of time before giving it a chance. The trick is that to memorize a game, you sort of have to understand it. It’s possible to just memorize moves like you’d memorize a list of random words, but it will be 10x harder than just understanding what’s going on.
If you understand what’s going on, you end up memorizing the game in a series of chunks, instead of a series of moves. For example one miniature that I’ve memorized is this game between Peter De Bortoli and Botond Smaraglay. I can recite move by move, but the way I remember it is roughly “Smith Morra gambit, knight development, bishop development, scare off bishop, threaten queen trap, knight blunder, queen trap”. Memorizing a couple king’s gambit games has definitely improved my king’s gambit play by giving me more ideas.
Very interestingly, this one person thought that compared to these other activities, actually playing chess does not improve your chess that much. Nor does coaching. This seems to match what this paper found, where the strongest predictor of chess skill is precisely hours of solitary practice, moreso than hours played at tournaments. It also makes sense to me: When playing chess you are not always running into novel situations, for example the openings are very mechanical. Puzzles get at hard situations and memorization builds strategic awareness.
Chess coaches
We don't have examples of chess masters that got to mastery without ever playing the game, doing just puzzles and memorization. But we do have examples of chess mastery without one component that some may think is required, tutoring.
In addition, much of the knowledge provided by coaches is available in books and computer programs, and for many beginner players, the financial investment in coaching sessions and the discipline necessary to prepare for regular lessons is neither affordable nor desirable. Indeed, some prominent self-taught players argue that it is possible, and perhaps more practical, to learn the game without the help of a coach. In a preliminary study of the relative importance of various chess activities, Charness et al. (1996) surveyed tournament-rated chess players from Europe, Russia, and Canada to ascertain their beliefs about the relevance of different chess activities to their overall chess skill, and to collect estimates of the frequency and duration of time spent on these different activities. Although participants in this study rated active participation in tournaments as slightly more relevant to improving one’s chess skill than serious analysis of positions alone, subsequent regression analyses revealed that cumulative serious solitary chess study was the single most powerful predictor of chess skill ratings among a broad set of potential predictors, including tournament play and coaching. (Charness et al., 2005)
Most (80%) chess players in the sample studied by Campitelli & Gober (2008) employed coaches and presence of a coach correlated with rating, albeit not as strongly as say the number of chess books owned. Is coaching a marker of seriousness, or does it independently lead to skill? The paper doesn't quite test this to my satisfaction.
Proof of possibility (Can you become a chess grandmaster without a coach?) exists, but they are rare. In practice, why do players get a coach? The most immediate answer is that they believe they will get better at chess with vs without the coach. There may also be other reasons: a coach may help keep the player accountable, putting in enough hours of practice every day. Maybe having a coach makes the overall practice more enjoyable as well. And they reduce the psychological burden of deciding how to train and what resources to use, albeit they replace that with what coach to employ. I suspect that in terms of raw improvement, except perhaps once one gets to the level where you need to analyze specific players to beat (Grandmaster who plays other GMs), coaches don't accelerate learning in chess. They might have had that effect in the past, back when chess engines were weaker and chess training was less formalized, and the belief in coaching has continued to our days.
My takeaway from chess is, on the optimistic side, that we have managed to scale expert performance in this domain to the point where no teaching is needed: tacit knowledge can be effectively transmitted. Moreover we have also found effective ways of doing so; and these ways do not involve doing the activity (chess) over and over, but rather involve especially chosen subfacets of the activity (chess puzzles that capture interesting situations). The downside is that this is still extremely time consuming: there doesn't seem to be optimizations or techniques that can lead one to mastery in a handful of months. If most domains are like chess, then accelerated expertise is a pipedream and one has to put in the hours over a few years. But to somewhat counter that, the techniques developed in chess (and language learning) can still be extended to other domains. Instead of masters we may be able to train advanced journeymen whereas that was previously imposible without a tutor. That's still some form of success!
Is everything like chess?
If everything is like chess, as in requiring a long time to master even with the best learning techniques in the world, then we shouldn't hope to be able to learn much faster in other domains. But we know there are domains that are easier to master; learning how to proficiently use a micropipette doesn't take years. Other domains that don't have a long pedagogical tradition currently will take years and it may seem impossible to shorten that, but that's a failure of the imagination. We haven't even tried the method that I think would work, other than in language learning, there we get to a period of around 1 year for learning with the right methods. I don't have a good handle on how long something "should" take. Naively, this span of time should correlate with the number of items to be learned and their interrelations. Perhaps someone has somewhere a database of tasks and time it takes to learn them and this can be verified experimentally, and from there we could extrapolate to more complex domains.
Software engineering
I used to work as a software engineer. As with a nontrivial chunk of the software engineering population, I taught myself how to code. Many people can learn how to code in a day, in that they can learn about conditionals, loops or functions, but that wouldn't be enough to do much meaningful with that particular programming language. What does a principal staff engineer know that the novice doesn't? A nontrivial amount of it is not quite tacit knowledge: it is cached explicit knowledge; knowing what libraries to use (as opposed to spending a day traversing Reddit, StackOverflow, and playing with multiple ones to find the one that meets the need). But there is tacit knowledge as well. Example: If you need to write a bunch of code to get data from some source, run some operations with it, then send messages elsewhere, how abstract should that be? Should the system be able to work with any source of data? Should arguments be passed to functions as big "config" objects, or individually? Should anything special be done about database connections (Like designing a singleton instance, knowing that it's useful to leave connections open for reuse). How efficient should it be, given project requirements? There are books on these sort of questions (Section 2.6 of this for some) but just reading that wouldn't be enough to be good at it, one has to do the thing. Expert engineers can rely on their past experience built over the years to think about these matters.
But what if we had a library of videos of expert programmers showing how it's done? This already exists in a crude form: live coding. It has all the elements discussed in previous sections: It's not an expert explaining the domain but actively performing the activity to be taught. They contain mistakes and how to fix them. The experts also add commentary, which is even better as we can't see into their thought process, just their screen. As far as I know watching these videos are an underused tool in teaching software engineering. There is no curated library of videos one should watch to get good. But if we had one, would that be it? Maybe.
Managing experts
I have been using "tacit knowledge" to refer to "expert tacit knowledge". One of the goals when writing this essay was to reason about second order knowledge: Not knowledge of X, but things like knowledge about X, the history of X, or managing experts in X.
Ben Reinhardt has a heuristic in his notes, that people who have done a thing should be in charge of that thing because It’s extremely hard to build up intuition for a thing without having done it. So at the end of the day ‘having done a thing’ is actually a heuristic for ‘has intuition about this thing.’.
In its face, yes, this is a good heuristic. But it's unclear how weighty it should be given other considerations. For example the heuristic would admonish us not to have Elon doing Elon things (When he started SpaceX), Ben doing PARPA (he's never managed a research agency before), or for that matter a lawyer starting a large and successful pharma company. Whereas the heuristic is true, so is another: That outsiders can lead to higher variance outcomes. This is good when exploring the frontiers of the possible. One person's tacit knowledge and hard earned intuitions for a field are another's biases and unjustified preconceptions. Sometimes an unqualified outsider does end up showing the veterans that they were wrong: such is the natural order of things.
There's another issue with the heuristic: being in charge of things is also a skill; the same goes for teaching a skill. A great researcher can be a poor teacher can be a poor research manager.
Collins and Evans have a quote in their book about Gary Sanders, the LIGO project manager. LIGO is a large piece of equipment built to detect gravitational waves that is incredibly complex. Sanders had never built anything like LIGO and yet was put in charge of it, growing into that role, being able to manage a project in a domain, talk about the domain, without being able to work in that domain directly:
I was concerned that I just would not understand it. But I’ve found that, remarkably, what you call interactional expertise was not hard to achieve. I couldn’t design an adaptive optics system but I really do, after six to nine months in the field, I really do understand the different kinds of adaptive optics and the way that they work and I can draw a schematic and define the algorithm, and understand the technological readiness of the different techniques—which ones are really ready to apply to the sky and which ones need to be demonstrated and certain components have to be developed. . . .
I can sit down with a bunch of adaptive optics experts who will come to me and say “Gary you’re wrong—multi-object adaptive optics will be ready at first light and it will give the following advantages . . .” and I shall say “No, it’s multi-conjugative adaptive optics” and I can give them four reasons why we should go with multi-conjugative adaptive optics based on the kind of science we want to do, the readiness of the technical compo- nents, when we need them, and so on, and I will see as I am talking about it that the room is looking back at me and saying “He does have a line, he’s thought it through.”
[But] if someone said to me, “OK Sanders, we agree with you, now go and design a multi-conjugative adaptive optics system,” I couldn’t do it. I couldn’t sit down and write out the equations. . . . But I can draw a diagram of what each part does, where the technological readiness of each one is—what the hard parts are—I know the language and I actually feel qualified to make the decisions.
Looking back to his period at LIGO, he said:
I can’t design the LIGO interferometer. I can’t sit down and write down all the transfer functions and work out the noise budget like [named scientist] can. But if he gave a talk on it I could follow it. I can understand the important parts and the hard parts, partly by listening and partly by quantitatively understanding, but I couldn’t come back and compose the symphony. But I was in a position where I had to decide. So it’s a matter of who I listen to and which parts seem like they carry the argument—what it is that we want. . . . That’s more than interactional but it’s not quite contributory in, I think, your usual sense of the word (Gary Sanders, LIGO Project Manager)
But Collins and Evans add:
In most specialist domains in the field they have to manage, the manag- ers, then, have interactional expertise but not contributory expertise.32 Does this mean that their technical expertise is no greater than that of, say, a sociologist who has developed interactional expertise? To say “yes” seems wrong—as Sanders says, there is something going on that is a bit more than interactional expertise. The resolution seems to be that, although, as we can see, contributory expertise is not required to manage even the science of a scientific project, management does need kinds of expertise that are referred from other projects. The managers must know, from their work and experience in other sciences, what it is to have contributory expertise in a science; this puts them in a position to understand what is involved in making a contribution to the fields of the scientists they are leading at one remove, as it were. Managers of scien- tific projects with referred expertise would manage better (as well as with more authority and legitimacy) than those without it.
The experience in other fields is applied in a number of ways. For example, in the other sciences they have worked in, they will have seen that what enthusiasts insist are incontrovertible technical arguments turn out to be controvertible; this means they know how much to discount technical arguments. They will know how often and why firm technical promises turn out not to be delivered. They will know the dangers of allowing the quest for perfection to drive out the good enough. They will have a sense of how long to allow an argument to go on and when to draw it to a close because nothing new will be learned by further delay. They will have a sense of when a technical decision is important and when it is not worth arguing about. They will have a sense of when a problem is merely a matter of better engineering and when it is fundamental.
Which also coheres with something that is maybe in a different note: Ben's rule of thumb for PARPA PMs is having done research in some physical domain (Not mathematics or CS say), it doesn't have to be the exact same domain, but one has to be aware of the kind of activity research entails, to expect the unexpected, to be comfortable with failure, trial and error, debugging experiments. However, Collins and Evans then point to Leslie Groves, someone far from being a physicist that directed the Manhattan Project. Groves was experienced in managing construction projects and picked Oppenheimer to oversee research. The Manhattan Project example shows that the second heuristic: "Managers should have experience managing" can work as well as "Being in charge of X only if you have done X". Ideally one would choose someone that has experience both in X and overseeing X. But as with many things which heuristic wins is going to depend on context: The Manhattan Project was very construction-heavy, and Groves never tried to micromanage the scientists, he left that to an actual scientist, Oppenheimer. In that particular case it may have been that Oppenheimer would have been overwhelmed by managing the entire project (Or bored, or his talent wasted, pick one). But in the case of a smaller operation like a research program, then acquaintance with the domain could regain primacy and become the superior heuristic.
Lastly there's Elon. Elon breaks the schema because when he started SpaceX he was not a rocket engineer nor a manager of anything physical (He was coming from a payments background). What Elon brings to the table is being able to learn fast and being a good judge of talent. Sure he read books on propulsion, but he didn't bother trying to do the actual design himself from scratch, instead he found a promising propulsion engineer, Tom Mueller, and hired him. The same is true for Blake Scholl. A priori one wouldn't have chosen a Senior Director at Groupon to lead a supersonic flight company. But what if said person spends time understanding the domain, is self-aware enough to understand what he doesn't understand and, crucially, can judge other's talent then it seems like a whole different case.
Scaling expertise
So how do you scale tacit knowledge (And the related and as important private explicit knowledge)? Inasmuch as that is part of what makes experts experts, this is tantamount to asking how do we accelerate expertise. The US DoD has been trying to do this for a while.
What they seem to have gotten to is that you can accelerate expertise somewhat, and that to do so you need very rich environments, simulations of the domain to operate on. Simulations are harder to construct than just watching recordings of experts, but they definitely are not trying to enumerate a series of principles that defines what an expert is doing and teach that to novices. There's no way to make a soldier "work with civilians" (What the DoD was trying to do in the link before) with principles. Rather, you sit down with experts and walk them through a situation and note down what they notice (for example), then do the same with novices, then show the novices what the experts picked up. The experts give some reason for why they picked what they did (Say a firefighter may say that the smoke was thicker than expected for that situation) but even without that, being able to compare one's judgement with that given by the expert should induce some learning.
From the various examples through the essay: I want to see a learning system that consists of watching videos of expert performances of a given skill, and supplemented by some written material (Like one can supplement immersion in language learning with grammar books). This could be in VR instead of video, but video is a good first point to start. The key elements:
- The material would be a large library of examples of the activity being performed. Not instructional (i.e. staged, or classes) material.
- If possible, the expert should provide some commentary when performing the activity.
- The material has to require engagement at some point, as opposed to passive watching or reading. At minimum this engagement could be requiring some form of memorization, but could also be trying to guess what comes next, trying to guess what facts would an expect consider salient.
- Periodically one should check progress by doing the activity that is being learned.
- Design of this course should be informed by areas where we have extensive pedagogic traditions, like language learning or chess
Conclusion(s)
The essay above is somewhat meandering, so if you want to pin down exact assertions, out of context, here are a bunch of them that now probably make sense given the rest of the essay:
- Tacit knowledge is real. There is knowledge experts have, but cannot explain or write down.
- Experts have more than tacit knowledge, especially private explicit knowledge. This can be gained to some extent by talking to the experts.
- Private explicit knowledge is hard to scale due to incentive issues: it's private for a reason. Sometimes it's because NDAs, sometimes because the expert gains nothing from giving away their knowledge which perhaps is a source of professional advantage.
- The bulk of learning a scientific field is codified in publicly available information. This is different from the knowledge required to being able to work in the field. The closer one gets to execution (vs knowledge in the abstract) the less knowledge is publicly available.
- This is not true for other domains that have less of a tradition of extensive codification, like engineering
- Having just a list of the propositions that are in a bunch of papers is not enough to learn a field. But with enough such observations one can peek behind the papers and see why things are the way they are. Think of yourself as a human GPT-3; the internet doesn't teach how to think, but somehow reading a lot made GPT-3 somewhat smart. The same is true, I claim, for reading a lot of papers.
- There are ways to get better at something besides doing that something. Chess puzzles and memorization beat the actual playing of chess at gaining chess skill. Field connoiseurs that don't have to do research themselves (Which frees up time) can quickly match the knowledge of those working in the field, even if they never acquire the knowledge to work in it. The time spent pipetting or setting up the Nth run of a thermal cycler can instead be spent acquiring more information.
- We can accelerate learning with massive input of examples in context.
- Rote memorization seems useless at first, given that one can quickly search on the internet. But the point of memorization is not just fast retrieval: it is to build internal structures, maps, frameworks, chunks, of a domain, which then can be deployed to better navigate that domain. In some domains, this can be part of the solution to scaling expertise.
- How one learns a field should depend on what the goal is. There is no need to spend three years reading aging biology papers if all one wants is to know enough about companies in that space to invest in them, or to find what the open questions are, and find promising talent to lead projects to tackle them.
- Talking to enough experts can get you enough knowledge to quickly validate an idea, answer a question, and get a good enough feel for a field.
- To manage a project in a field, or to pinpoint the rough set of open problems in a field one does not need the deep knowledge that an expert may have. But having experts validate the derived set of problems should be part of the process.
- Expert identification is an art, one needs to know what the right questions to ask are!
- The understanding derived from talking to experts is shallower than that obtained from reading papers. Both are inferior to being embedded in a field, or working in a field.
- The heuristic "have done the thing" -> being able to manage the thing makes sense. As does "being a good manager" -> managing the thing. This heuristic doesn't always work in the presence of smart generalists that can find good talent to support them.
- Tacit knowledge cannot be taught in the usual way (by explaining it), rather it can be conveyed in indirect ways by demonstrations, apprenticeships, simulations, videos, or libraries of case studies.
- Stories, case studies, or even business books are easy to dismiss as N=1 anecdotes. I used to think that. The usual tabulated neat datapoints the STEM minded are used to cannot capture the fullness of complex skills out in the wild. A collection of anecdotes is the kind of data we need to transmit tacit knowledge.
- Embeddedness in a field will be very useful to get the last 10-20% of knowledge in the field. Because no one can immediately list all the relevant facts, hanging out with people in the field (in conferences, online seminars, or the local bar or cafe) will increase the probability that one will come across new facts, perhaps contained in tangential remarks. Different situations will make salient different facts to the expert, so enough interaction with experts will increasingly explore the space of their knowledge.
References
Some books and articles I've read in the process of writing this essay
- Klein, Gary A. Sources of power: How people make decisions. MIT press, 2017.
- Hoffman, Robert R., et al. Accelerated expertise: Training for high proficiency in a complex world. Psychology Press, 2013.
- Collins, Harry & Evans, Roberts. Rethinking expertise. University of Chicago Press, 2008.
- Cedric Chin's Commonplace
- Salvatier, John. Reality has a surprising amount of detail
- Reinhardt, Ben. Working notes
Changelog
- 2022/04/08: Thanks to Max Krieger for pointing out typos and odd sentences
- 2022/05/24: Thanks to Barry Cotter for pointing out typos and odd sentences
Citation
In academic work, please cite this essay as:
Ricón, José Luis, “Scaling tacit knowledge”, Nintil (2021-12-10), available at https://nintil.com/scaling-tacit-knowledge/.
Backlinks
- On Reboot's Ineffective Altruism
- Elon's decision making: an anecdote compilation
- Images and Words: AI in 2026
- Metascience: invariants and evidence
- Links (54)
- Links (61)
- Links (76)
- Massive input and/or spaced repetition
- Applied positive meta-science
- Limits and Possibilities of Metascience
- New Science's NIH report: highlights
- Notes on 2021
- Evidence and the design and reform of scientific institutions
- Talent: a review
Comments