Fund people, not projects II: Does pre-grant peer review work?
In a previous post I reviewed the evidence behind the effectiveness of two awards targeted at promising researchers, funding them more and for longer. The conclusion was that the evidence is not very strong and that the extent to which "Fund people" makes sense depends on other factors that we should also investigate.
Both the HHMI Investigator and NIH Director's Pioneer Award are targeted at scientists that are expected to perform well. The each require applicants to have shown success already. Ultimately, those that get those awards do produce more highly cited work. But is that because HHMI/NIH picked those that were going to win anyway, or because of the award itself? Or a combination, of course.
It would be convenient if "past success doesn't guarantee future returns" in science; that while some scientists may seem successful, it's just because they are lucky. If all scientists are equally talented (An assumption that I'll call scientific egalitarianism) then "Fund winners" works and should be scaled to the entire system: We should expect rolling out HHMI-style funding to anyone leading to substantial improvements to the rate at which science occurs. On the contrary, if scientific talent is unequally distributed, perhaps highly so ("scientific elitism"), then dishing out additional time and money will lead to relatively smaller increases in scientific productivity.
It could also be that despite some scientists being intrinsically more likely to produce better work, that is so hard to see that it's not even worth trying. So this post will explore the extent to which pre-grant peer review helps to improve the quality of the work being funded.
Predicting success in science
First, we can look at whether it is possible to predict success in science in general. Given the career of a scientist so far, how much can we tell about their future?
Azoulay's own paper has a model in it that can predict who will end up becoming a HHMI investigator. Based on a sample of 466, Table 5 shows that their best model predicts 16% of the variance where the coefficients that are statistically significantly different from 0 are a measure of how many top 1% publications they have published, and being female; in fact being female seems 4x more predictive of HHMI selection than publishing a lot. This doesn't seem right, here are some potential explanations:
- Women are after all better researchers than men (all else equal) even after accounting for publications and HHMI reviewers know this, or
- Perhaps the rest of the funding ecosystem is biased against women, leaving more highly talented women available for HHMI to fund them relative to men, or
- HHMI has biased their selection process to favor women
The case for peer review
I want to start here with Li & Agha (2015) as it's a relatively recent paper with by far the largest sample, and one that finds a result that runs counter to the anti-peer review narrative that seems prevalent in some corners of academia: they find that getting a lower (better) score by a study section at NIH leads to more citations, patents, and publications coming out of that grant in a dataset covering all R01s given by NIH in the period 1980-2008, 56% of which are new applications and the rest are grant renewals.
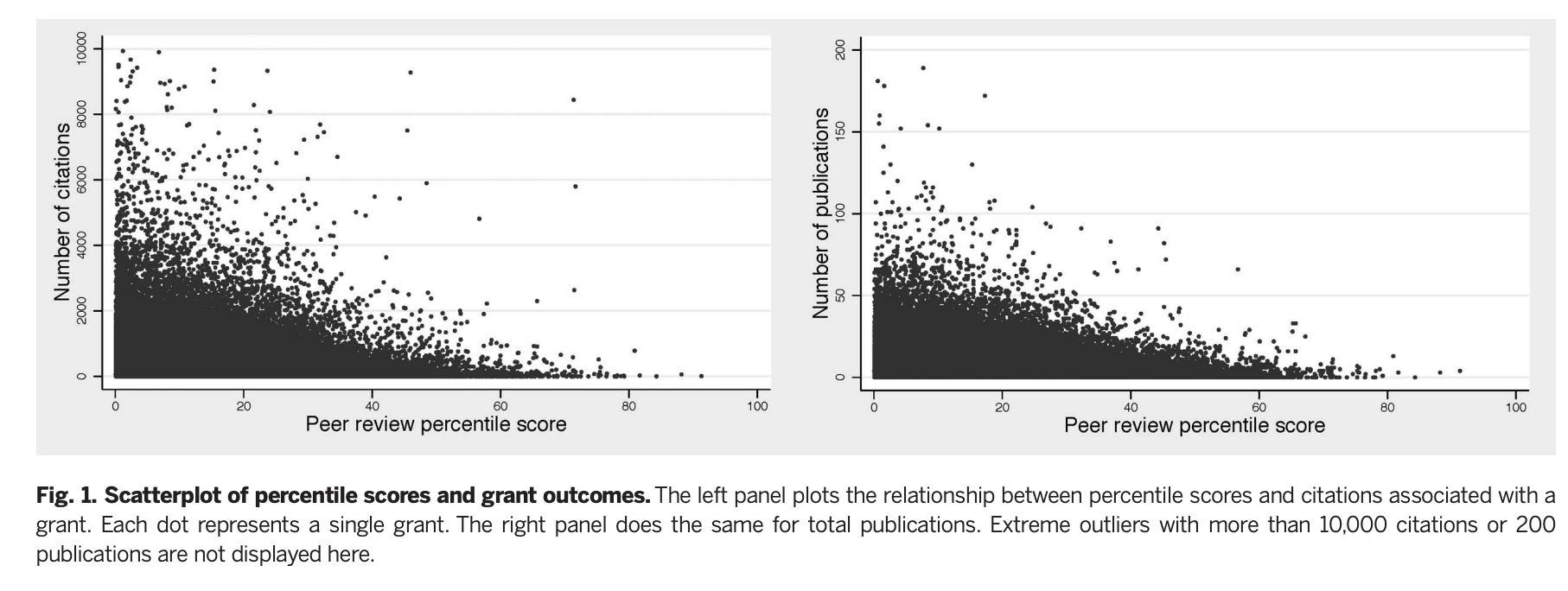
Li & Agha note:
The median grant in our sample received 116 citations to publications acknowledging the grant; the mean is more than twice as high, 291, with an SD of 574. This variation in citations underscores the potential gains from being able to accurately screen grant applications on the basis of their research potential. [...]
For a 1-SD (10.17 point) worse score, we expect an 8.8% decrease in publications and a 19.6% decrease in citations (both P < 0.001). This suggests that scores for grants evaluated by the same study section in the same year and assigned to the same NIH institute are better than randomly allocated.
Is this because the reviewers know who the applicant is, or are they using the applicant's past history to decide what to fund? There is some of this going on, and it makes some rational sense; however, the strong correlation between score and outcome doesn't go away even by controlling from other observables:
Controlling for publication history attenuates but does not eliminate the relationship: a 1-SD (10.17 point) worse score is associated with a 7.4% decrease in future publications and a 15.2% decrease in future citations (both P < 0.001).
They don't find that being for longer in the system moderates this relation, to the extent that more established PIs produce more successful work, in their dataset, it is because they do produce better grants.
Next they look at the relative impact of peer review on picking winners vs weeding out losers (Or grants that won't lead to a lot of citations)
But in their analysis the authors are looking at those that are in the top 20th percentile. In that restricted sample, do scores predict success?
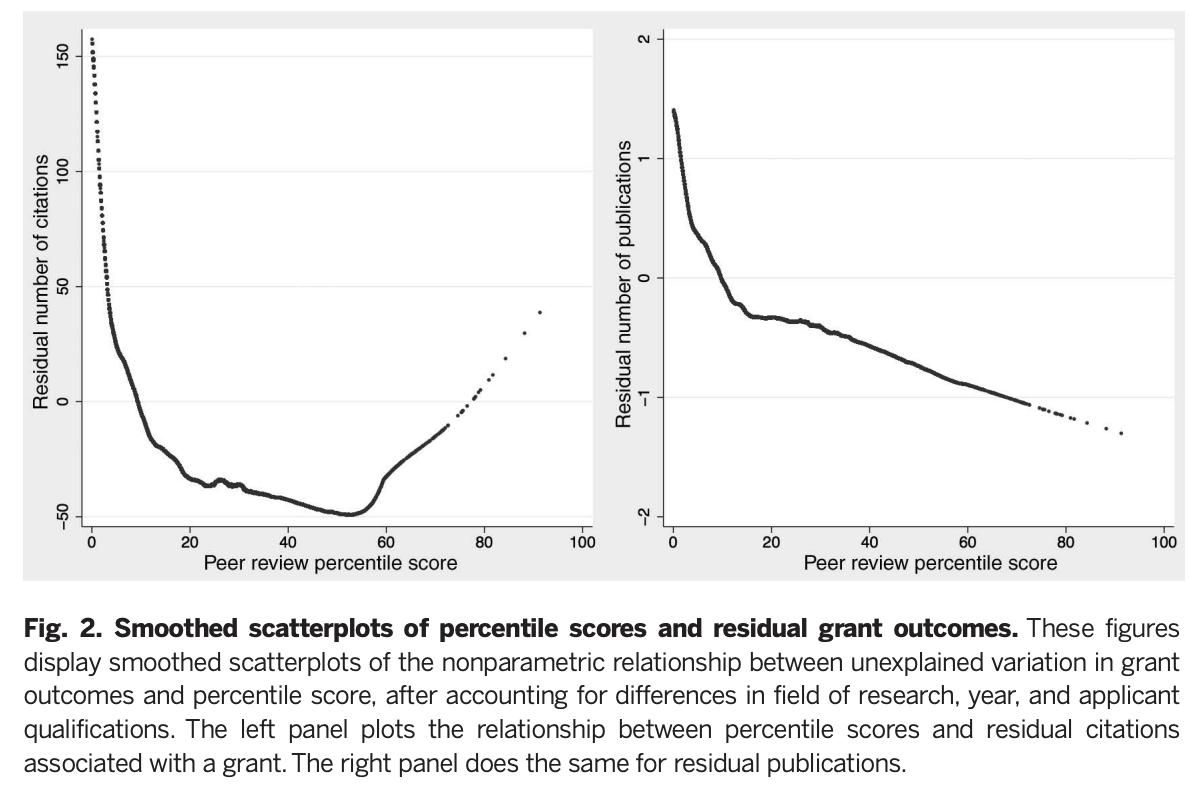
What this figure shows is the result of trying to substract everything that shouldn't matter (institution, past record, gender, time in the field) with the intention of leaving what should (Namely, grant quality). If you don't need grant quality to explain citations, then the curves above would be flat. But they are not; rather they do show that lower (better) percentile scores are associated with exponentially more citations, and somewhat with publications, especially when applications under the 20th percentile are considered. On the right tail are grants that seemed bad to the review section, but that were funded anyway. Here someone applied additional judgement to rescue a few promising papers, overruling the study section. This worked: Those papers do get more citations.
Lastly, they look at whether this predictive power is similar across all classes of publications (top 0.1%, 1%, 5% etc) in addition to leading to more patents. They find that study sections are actually quite good at discerning this great work:
As reported in Table 2, peer-review scores have value-added identifying hit publications and research with commercial potential. A 1-SD (10.17 points) worse score is associated with a 22.1%, 19.1%, and 16.0% reduction in the number of top 0.1%, 1%, and 5% publications, respectively. These estimates are larger in magnitude than our estimates of value-added for overall citations, especially as we consider the very best publications. The large value-added for predicting tail outcomes suggests that peer reviewers are more likely to reward projects with the potential for a very high-impact publication and have considerable ability to discriminate among strong applications. A 1-SD worse percentile score predicts a 14% decrease in both direct and indirect patenting. Because of the heterogeneous and potentially long lags between grants and patents, many grants in our sample may one day prove to be commercially relevant even if they currently have no linked patents. This time-series truncation makes it more difficult to identify value-added with respect to commercialization of research and means that our estimates are likely downward biased. [...]
This finding runs counter to the hypothesis that, in light of shrinking budgets and lower application success rates, peer reviewers fail to reward those risky projects that are most likely to be highly influential in their field (1, 2). [...]
Our analysis focuses on the relationship between scores and outcomes among funded grants; for that reason, we cannot directly assess whether the NIH systematically rejects highpotential applications. Our results, however, suggest that this is unlikely to be the case, because we observe a positive relationship between better scores and higher-impact
And that once one gets to the bottom of the distribution, success can be predicted algorithmically:
We don’t find evidence that the peer-review system adds value beyond previous publications and qualifications in terms of screening out low citation papers. Better percentile scores are associated with slightly more publications in the bottom 50% of the citation distribution.
This is a fortunate conclusion, because it means that it's possible to use bibliometrics to select a candidate set of sufficiently good scientists, and then use human reviewers to select among them.
Gallo et al. (2014), using a dataset of 2063 grant applications1 submitted to the American Institute of Biological Sciences (AIBS) find a pattern that seems coherent with the Li & Agha study, where lower (better) scores lead to more normalized citations. In particular, you can see here that there was no highly cited work (>20 TCR) with a score under 2, and the grant that led to the most citations had a high score (One that the authors removed from later analysis, treating it as an outlier! They shouldn't! Impactful science is all about these!). Now you can imagine here if you didn't have that point up there you might conclude that peer review doesn't matter that much (Perhaps under a score of 2), so having large samples that are assessed sufficiently after the grant was awarded (to allow for great work to be discovered and cited) is key. What they did find (not shown here) is that funding or seniority of the researcher alone does correlate with impact.
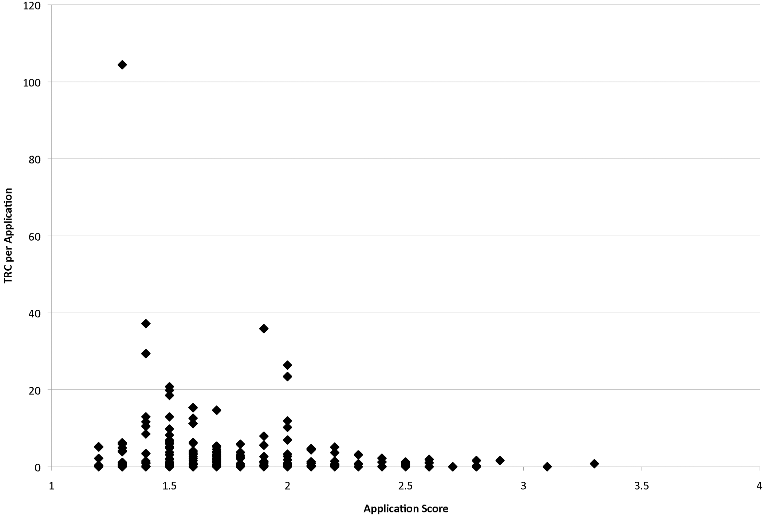
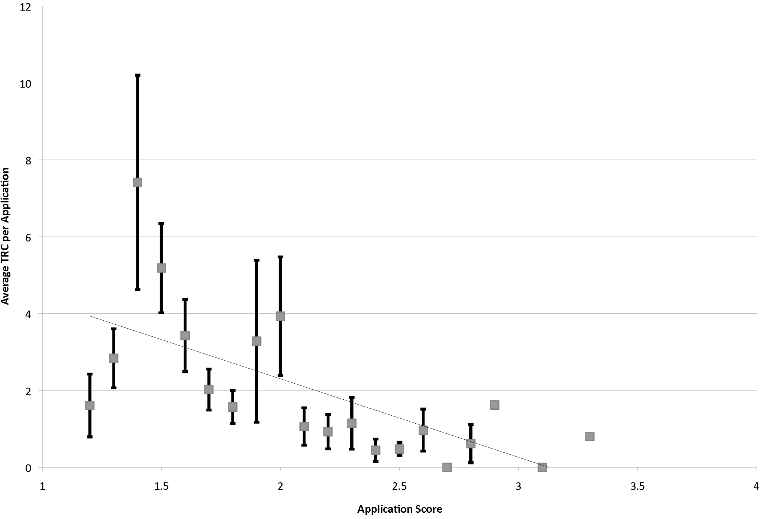
One reason the authors think their results are not quite those of other papers that find no effects is that NIH's study sections are more general than the more ad-hoc highly specialized panels AIBS uses, another is that AIBS is more permissive than NIH in funding applications with low scores (Though this is not that likely, their funding rates were even more strict than NIH's at 8% by 2006). As one may expect, when more grants were funded, the work they led to had more citations. Was this because the reviewers had a larger pool to pick from? Or just because there were more grants, period? The authors suspect it's the former, and they do have a figure showing that the average annual score was higher the more submitted applications there were2 .
Park et al. (2015) are able to leverage a natural experiment to see if NIH scores tell anything about quality. ARRA was a pot of money that went to various places during the 2009 recession. This enabled NIH to fund research that otherwise would not have been funded, they found that those extra grants were not as productive as the ones NIH was already awarding, so there are indeed decreasing marginal returns, and NIH can choose what's better to some extent. Opponents of pre-award peer review can't quite say that these projects are obviously so low quality that reviewers can distinguish them: Paylines for individual NIH institutes are already very strict, so the additional grants that are getting funded under ARRA are not grants scoring 60 or 70, but perhaps 20-30.
We find that regular projects on average produce per-dollar publications of significantly higher impacts (12.5%)thanARRA projects and that this difference is primarily driven by R01 grants, the largest funding category among NIH grants. We find a similar result for the (dollar-adjusted) number of publications, and the gap is even larger: regular projects produce 17.9% more per-dollar publications than ARRA projects, and R01 grants seem mainly responsible for that difference. Overall, regular projects appear to be of considerably higher quality than ARRA projects.
Weiner et al. (2015) pool together papers chosen as "best" from a dozen of CS conferences spanning topics from ML to Security in the period 1996-2012 and ask whether these "best" papers are cited more than a random paper from the same conference. That probability is quite high, from 0.72 to 0.87. However, a potential explanation the authors do not consider seriously (They say that the best papers are hard to find in the conferences websites, but surely people in the field, especially if they were in those conferences, know what those papers are) here is that maybe "blessing" a paper with the "best" title in and of itself causes the extra citations. Unlike with NIH grant peer reviews that are not public, everyone knows what the supposedly good papers are so they are more likely to be read and cited.
The case against peer review
Fang et al. (2016) take issue with the above analysis. First, they stress that other work has found that there is no correlation between percentile score and publication productivity. Why did Li and Agha find what they find? Fang et al. say it's because they included a lots of grants with scores over 40 that would not be funded today (I don't find this plausible, eyeballing the charts provided shows the relation still holds, plus the various figures use local regressions that would be unaffected by throwing away everything worse than the 40th percentile); they also claim that *this study did not examine the important question of whether percentile scores can accurately stratify meritorious applications to identify those most likely to be productive.*yet it seems that they did so: Higher scores go hand in hand with higher productivity in Li and Agha's work. They have this figure in the paper where they show that above the 20th percentile there doesn't seem to be a lot of difference in the citations accruing to papers in each bucket, with the exception of those at the very top.
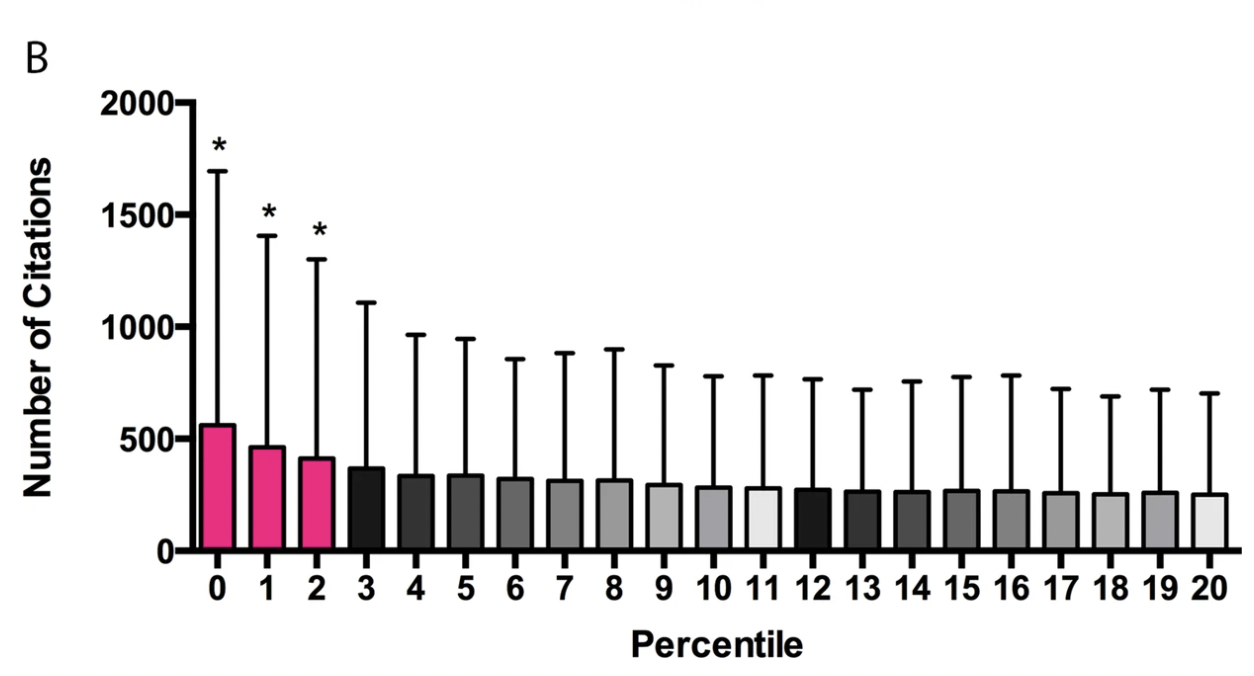
And they also point out that if one wanted to know if a publication ends up in the top 50 or bottom 50 of the distribution of publications by citation count, the p
Citation
In academic work, please cite this essay as:
Ricón, José Luis, “Fund people, not projects II: Does pre-grant peer review work?”, Nintil (2021-01-08), available at https://nintil.com/grant-peer-review/.
Comments