Fund people, not projects I: The HHMI and the NIH Director's Pioneer Award
So there's this paper, Incentives and Creativity: Evidence from the academic life sciences (Azoulay, Graff Zivin, Manso 2011) that shows that Howard Hughes Medical Institute (HHMI) investigators (who are funded for a longer term and in a more open ended way) outperform those of the National Institutes of Health (NIH) that have shorter review cycles and more concrete grant proposals. This is seen as a vindication of the "fund people, not projects" paradigm. However, the effect size reported is huge , perhaps too good to be true, and the extent to which this model can scale is debatable, as Azoulay himself also says that it is not clear how well this model can scale. HHMI is very much focused on a narrow elite.
Similarly, while science generates much of our prosperity, scientists and researchers themselves do not sufficiently obsess over how it should be organized. In a recent paper, Pierre Azoulay and co-authors concluded that Howard Hughes Medical Institute’s long-term grants to high-potential scientists made those scientists 96 percent more likely to produce breakthrough work. If this finding is borne out, it suggests that present funding mechanisms are likely to be far from optimal, in part because they do not focus enough on research autonomy and risk taking. (We need a new science of progress)
NIH has their own HHMI-style throw-money-at-the-best program, the Director's Pioneer award (DP1)1 which also seems to produce great results. DP1 grants are similar to the HHMI Investigators program (700k per year vs ~1M at HHMI) and as selective (11 pioneers per year vs 20 for HHMI). They are not as long-lasting as the HHMI ones however in that they last for 5 years while HHMIs enjoy a theoretical 7 and a practical 15 years of funding.
Both have been lauded as exemplary programs that cause more good science to happen that otherwise would not.
So this seems like an important "huge if true" fact. Even if, as Azoulay suspects, this model cannot scale, it is reasonable to think that the scientific elite that would benefit from this class of funding is comprised of more than the current 250 HHMI investigators and 50 or so DP1 awardees.
So with this setup, let's look at first the general question (people, not projects) and then the specifics of NIH and the HHMI once we have a framework to assess them.
Fund People, not projects
The usual way grants are allocated is a process whereby a scientist says they want to do specific piece of work X and then they get money to do that. In practice, researchers have already done part of what they say they will do (And use that data to support the application), and will use part of the funds to work on other things they may want to work on so they can do as they please with part of their time and money. But for the most part, they are working on what they say they are working on. R01 grants, the bulk of NIH's funding, run for 5 years (And this has gone up over time), not too dissimilar, at first glance, to the HHMI's 7.
With DP1 and HHMI, researchers do not submit a grant proposal for something specific they want to do, they submit their resume and a broad summary of what they are going to be working on. This research program (3k words) is shorter than a usual Nintil blogpost, and substantially shorter than one of the sample R01 grant applications from the NIAD's website which are over 5x longer (excluding references and CVs).
Both are similar in that they can be renewed; if one wants to work on a 20 year project, in theory one can roll the same R01 four times, with the likelihood of being renewed starting at 30%. HHMI is more forgiving once one is in and in the event one is out: it provides two years of phase-out if a renewal is not successful and the renewal rate is >80% anyway, leading to a median of 16 years of support2 . Thus HHMI investigators can expect to be funded for longer, and because if they lose funding they don't have to be immediately looking for support, that should also help keep their eyes in the long term. This is not to say that HHMI investigators do not spend time applying for grants, you can search here for example Feng Zhang (HHMI since 2018) and see that he got a DP1 in 2020 as well as R01s in 2020 and 2019. Even David J. Anderson (HHMI since 1989) can be seen applying for R01s in the same site. This is because the HHMI award, generous as it is, covers the investigator's salary, some research budget, special expenses for expensive equipment, but not every expense, and not the hiring of additional lab members.
There are other differences, HHMI requires researchers to spend 75% of their time doing research, whereas in R01s there is no such limit. DP1s are required to work half of their time on grant-related research.
This brief discussion is just to highlight that the "fund people, not projects" approach, even when looked at by using their usual life sciencesexemplars, is not as clear cut as it may seem. It may be more useful to consider two extreme idealized approaches instead:
- Fund projects: A scientist proposes to do a specific, well defined project. There is an expected deliverable and there may be milestones involved that have to be met. Rather then being open ended and highly uncertain, it is roughly known to be achievable. The project should be ended if it's not meeting its goals.
- Fund people: A scientist is funded generously and have all their requirements for assistants and equipment met without paperwork or further reviews. They have zero accountability, and what they decide to research or publish has no bearing on the continuation of funding. In effect they have life tenure. They don't perish if they don't publish.
It's clear that there are advantages and disadvantages to both approaches; they are the explore/exploit tradeoff with another name. The first one is similar to the Focused Research Organization concept.
The second one sounds like tenure. But modern day tenure is not generally like this. Scientists are expected to continue to apply for grants and bring money to the university (The university gets a cut), as well as to grow their lab; in turn as they now have a lab they have some obligation to their students, who do need to publish in high impact journals in order to get ahead in academia. Tenure pays just the salay (and 9 months of it in the case of US tenure, as the other 3 are expected to be covered with grants). It does not cover the cost of any materials employed during the course of research, or the salaries of research assistants (Those also have to come from grants).
Donald Braben points out that before 1970 (or so)
tenured academics with an individual turn of mind could usually dig out modest sources of funding to tackle any problem that interested them without first having to commit themselves in writing. Afterward, unconditional sources of funds would become increasingly diffi cult to find. Today, they are virtually nonexistent.
The way forward for ambitious young researchers was once clear, therefore. All they had to do was to acquire the necessary qualifications, and then to find a tenured appointment. To say the least, that was not easy, but not substantially more difficult than it would be today. However, having served their apprenticeship, they were free. They may have had to overcome the inevitable peer pressure if their plans were controversial, but their peers did not have power of veto— see Poster 1 .Written applications were necessary if expensive equipment or large teams were required, but tenured researchers with modest needs would meet few obstacles.
This still sounds like modern day tenure! What has changed is that if more expensive equipment is now required (And this is most likely true in the life sciences than in theoretical physics) and that in turn requires grants, then academics now have that additional potential veto in a way that the cheaper experiments of the past did not have. And Braben can't argue that the new system selects for people that are good at getting grants. In the quote above he concedes that getting tenure was as hard back then; and plausibly to get tenure you needed the same things you do today.
The ones that come close to the "fund people" approach are not HHMI investigators, or the pre-1970 scientific community; those would be the self-funded independent scientists that were wealthy enough to be able to do anything they wanted. Alfred Loomis' story in particular, how he managed to have the best equipped lab in the US, paid out of his Wall Street profits, seems the closest to the platonic form of the fund people approach.
Fund people, not metrics?
Another distinction to be made here beyond people vs projects is how people or projects are selected. One can use impersonal metrics or one can get more personal and, eschew all bureaucracy and process and go full nepotistic. Though not intrinsically tied to "fund people", it is true that those approaches have historically been more linked to a personal approach. Ioannidis (2011) discusses various "fund people" approaches which include using mechanisms like lotteries or just funding everyone. This is one of the two missing sectors of the 2x2 quadrant (In red, missing):
In the HHMI process, a scientist get personally interviewed in the later stages of being funded. For R01s, there is a committee (a study section) that one will never see or meet. The Rockefeller foundation (post WWII) took it to an even more extreme level where they had ongoing personal connections with scientists at the core of their funding decisions. This approach runs counter to the way impartial bureaucracies work. An individualized approach either is extremely costly or it by necessity turns elitist as all those interviews and getting to know an individual takes time.
Warren Weaver, head of the Rockefeller Foundation's of natural sciences for over 20 years (And the man that coined the term "molecular biology") took some notes on how their officers allocated the funding to teach newcomers, some extracts below (Also note that the notes are full of advising newcomers to do X, but without taking X as a hard rule, more as guidance)
the interests and the general behavior of a scientist outside his laboratory - say in his own home - are by no means irrelevant and unimportant. Thus it is certainly not unfortunate or improper to visit, on trips, a scientist in his own home. [...] Talk with fellowship candidates in their own labs, sitting- on stools and smoking with them, rather than interviewing them under more formal circumstances. Talk about their work, their training, their families; seeking some initial topic that will put them quickly at their ease. [...]
In other words, the average person is neither very critical nor very frank about written recommendations. He assumes that the backers of other candidates will keep still about faults and limitations, and will use pretty rosy adjectives. So, in fairness to his candidate, he does the same. The remedy for this involves a lot of time and patience and energy. It involves slowly building up a relationship of close confidence with a large number of shrewd and hardheaded scientists; and talking with them about young men so continuously and generally that we build up in our own files an inter-locked web of objective and dependable information. [...]
This same general point explains why we think it is necessary and proper to be interested in the personal qualifications (as contrasted with the intellectual qualifications) of fellowship candidates. I know of a man who is almost surely the best expert on the genetics of oak trees in the world; but he doesn't take baths, and he swears so much and so violently that most persons just won't work with him. As a result he is living a frustrated and defeated life; and he not only doesn't have any students - he doesn't even have a job. [...]
Frequently other agencies, when discussing the quality of fellowship applications, say: "Among all our candidates there is a first group so undeniably and uniformly good that we could pick out of it only by some arbitrary procedure of selection. There is a final group so poor that we obviously should not be concerned with them. And then there is an intermediate group that is, so-to-speak, distributed along the curve that slides down from the high plateau of unquestioned excellence to the dismal valley of unquestionably poor quality. Where, in making our selections, should we draw the line in this intermediate group?" We have always claimed that the mere asking of this question reveals an unfortunate philosophy concerning fellowship selection. For we would say: "Deal exclusively with the first group of unquestioned excellence. Draw the line before you ever get to the intermediate group. That is, the question 'May I have this fellowship?' ought to be like the questions 'Is this egg fresh?' or 'Do you love me?' ." If you need to hesitate at all, the answer is surely no.
The reason why there may be personal factors involved may be that "how good of a researcher someone is" is hard to observe from their published work and related citations. I'll leave this question–predicting success in science–for another blogpost but I'll raise it here as it ends up being relevant for the next sections.
The halting problem in science
In computability theory, the halting problem is the problem of determining, from a description of an arbitrary computer program and an input, whether the program will finish running, or continue to run forever. Alan Turing proved in 1936 that a general algorithm to solve the halting problem for all possible program-input pairs cannot exist. (Wikipedia)
When funding a project (or a person) there is the question of who/what to fund and for how long. Both problems are coupled. If you commit to fund for X period of time maybe you won't attract the kind of person (or projects) that wants to do >X studies. Regardless of the who/what/how, the how much problem is there as well. The platonic "Fund people" modality outlined above could easily become an unproductive sink of resources. As a funder, if a scientist is not living up to the original expectations, should funding be withdrawn? That's what most funders would do. But at the same time, if funding can be withdrawn at any time that doesn't leave room to work on projects that will take longer to seem successful. Hence the standard solution from HHMI, NIH, Venture Research, the Rockefeller Foundation and everyone else: Fund scientists for a set period of time and review their performance after such period. Based on the review the award can be renewed or not.
The "people vs projects" come into play in how candidates vs what they propose to do play into the award decision. If NIH study sections, for example factors in the prestige of an applicant (conciously or unconsciously) then they are introducing some "fund people" into their methodology, inasmuch as prestige is correlated with actually being good. If the HHMI considers that a scientist, despite being talented, is not going to be pursuing research they consider worthwhile–and that informs their choice– they would be introducing an element of "funding projects". Maybe NIH is 80% projects 20% people and HHMI is 70% people 30% projects and Venture Research was 90% people 10% project.
There is some work (Vilkkumaa et al., 2015) on this question, and interestingly it speaks against the HHMI or Pioneer model; rather, to maximize breakthroughs their model calls for funding a lots of projects and killing them early if they don't show promise. But this paper falls short of the point I made ealier: Funders don't encounter a pool of projects passively waiting to be funded; rather projects are devised by researchers depending on what they expect will get funded. If the pool of projects is fixed ex-ante it may well be that the right thing to do is as Vilkkumaa et al. say. But if breakthrough projects are only proposed when scientists have a high confidence that they will be given plenty of time to work on them then their optimal model of letting a thousand flowers bloom will result in the flowers not growing in the first place.
Academic evaluations of the various models
The main reason I wanted to write this blogpost was to evaluate two pieces of work that I read a while back, what are perhaps the most direct evaluations of programmes that aim to give scientists plenty of time, resources, and importantly the freedom to steer their research.
The Azoulay 2011 paper
The Azoulay et al. (2011) paper I started this article with has been cited over 400 times and as far as I can see all citations I found were positive (And a search on scite.ai reveals the same). I couldn't see any attempt to poke holes in the paper. Given that the claims are in the "Huge if true" category (96% more likey to produce breakthroughs!), this disinterest on the side of the scientific community is somewhat worrying.
Right at the start there is a point that should be made explicit, they say that The typical R01 grant cycle lasts only three years, and renewal is not very forgiving of failure.
But as shown above, the last part is true (The HHMI has a wind-down funding period if there is a non-renewal) but the first part is not, only <10% of R01s run for 3 years or less. This is odd in that even by 2011 when the paper was published, it was still the case that R01s that ran for 3 years or less were uncommon. This stems from Azoulay et al.'s pooling of grants in the period 1960-2002, so we are looking here at how NIH used to be, not so much how NIH is today. Likewise, the HHMI investigators they look at are the 1993 to 1995 cohorts. This is so that there is enough time for citations to accumulate in order to judge what was impactful work, but again it gives us a picture of how HHMI was more than 20 years ago.
What the paper tries to do is compare HHMI investigators with a control sample from NIH-funded researchers that were awarded early career prizes. Their control sample is additionally tweaked to make it resemble more like the kind of profile that would get into the HHMI.
Relative to early career prize winners (ECPWs), our preferred econometric estimates imply that the program increases overall publication output by 39%; the magnitude jumps to 96% when focusing on the number of publications in the top percentile of the citation distribution. Success is also more frequent among HHMI investigators when assessed with respect to scientists’ own citation impact prior to appointment, rather than relative to a universal citation benchmark. Symmetrically, we also uncover robust evidence that HHMI-supported scientists “flop” more often than ECPWs: they publish 35% more articles that fail to clear the (vintage-adjusted) citation bar of their least well cited pre-appointment work. This provides suggestive evidence that HHMI investigators are not simply rising stars annointed by the program. Rather, they appear to place more risky scientific bets after their appointment, as theory would suggest.
We bolster the case for the exploration hypothesis by focusing on various attributes of these scientists’ research agendas. We show that the work of HHMI investigators is characterized by more novel keywords than controls. These keywords are also more likely to change after their HHMI appointment. Moreover, their research is cited by a more diverse set of journals, both relative to controls and to the pre-appointment period.
So there are various things going on in this paper, not just the headline "96% more publications in the top percentile"
- Overall publication output increases by 39% relative to non-HHMIs
- Highly cited research jumps by 96% relative to non-HHMIs
- Relative to themselves prior to the award, HHMis publish more
- HHMIs' fraction of low-cited works increases
- HHMIs tend to use more novel keywords relative to control
- HHMIs tend to use more novel keywords relative to themselves prior to the award
- HHMIs' work is cited by a more diverse set of journals, relative to non-HHMIs
- HHMIs' work is cited by a more diverse set of journals, relative to themselves prior to the award
HHMI is not looking to fund something "just good", they are looking for very special people that have already shown success, which is a substantially higher bar compared to what one would need to get an R01:
In a first step, the number of nominees is whittled down to a manageable number, mostly based on observable characteristics. For example, NIH-funded investigators have an advantage because the panel of judges interprets receipt of federal grants as a signal of management ability. The jury also looks for evidence that the nominee has stepped out of the shadow cast by his/her mentors: an independent research agenda, and a “big hit,” that is, a high-impact publication in which the mentor’s name does not appear on the coauthorship list.
The control sample is also, by the authors admission, not quite similar to HHMIs-to-be, the latter group is better funded on average, has more publications, as well as more top publications (2x more on average, median, as well as maximum). The HHMI investigator with the least top-25% or top 5% publications had 3 and 1, whereas that was 0 and 0 for the control group, reflecting HHMI's more stringent criteria. Note that their HHMI sample is 73 researchers whereas the control has 393. So even with a sample over 5 times larger, as shown below, not even the best of them is more successful than the best of the HHMI researchers. One would expect that if both were randomly distributed, in the presence of fat tails and even if HHMIs are a bit more successful on average, one would expect the best of them not to be better than the best of such a large sample. In fact, by the end of their careers, the control researcher that got the most top 1% citations (38) only got 1.8x that of the average HHMI researcher whereas the top HHMI researcher (144) got 18x more citations than the average control. So obviously, HHMIs are substantially better than the controls to an extent that seems hard to synthetically correct for.
By the end of their careers, have these differences multiplied? Here's a table of the before and after for both groups, without controlling for anything:
| HHMIs/Control pre award | HHMIs/Control end of career | Increase | |
|---|---|---|---|
| Mean n of publications | 1.31x | 1.46x | 1.11x |
| Mean n of top 5% pubs | 1.76x | 2.05x | 1.16x |
| Mean n of top 1% pubs | 2.28x | 2.65x | 1.16x |
| Max n of top 1% pubs | 2.7x | 3.79x | 1.4x |
| Average keyword age | ~1 | NA | NA |
| Journal diversity | ~1 | ~1 | 1 |
| NIH funding | 1.35x | 0.82x | 0.6x |
| Normalized keyword overlap | NA | 0.817x | NA |
| Early career prize winners trained | NA | 4.96x | NA |
| Nobel Prize winners | NA | 4.66x | NA |
So preliminary, pre-award HHMIs were more successful and post-award this difference relative to the controls grows even larger. Now what the paper wants to show is that the award caused these differences. For that the authors try to put everyone on the same starting line by controlling for various factors and then seeing what happens to the outcomes. This approach of course has its problems: It's not a true RCT. To normalize the samples, they assume that selection into treatment occurs solely on the basis of factors observed by the econometrician. Is the table presented in the paper, with citations, funding, etc sufficient? That is, if I give you this kind of data (Enjoy the scihub-provided snowflakes):
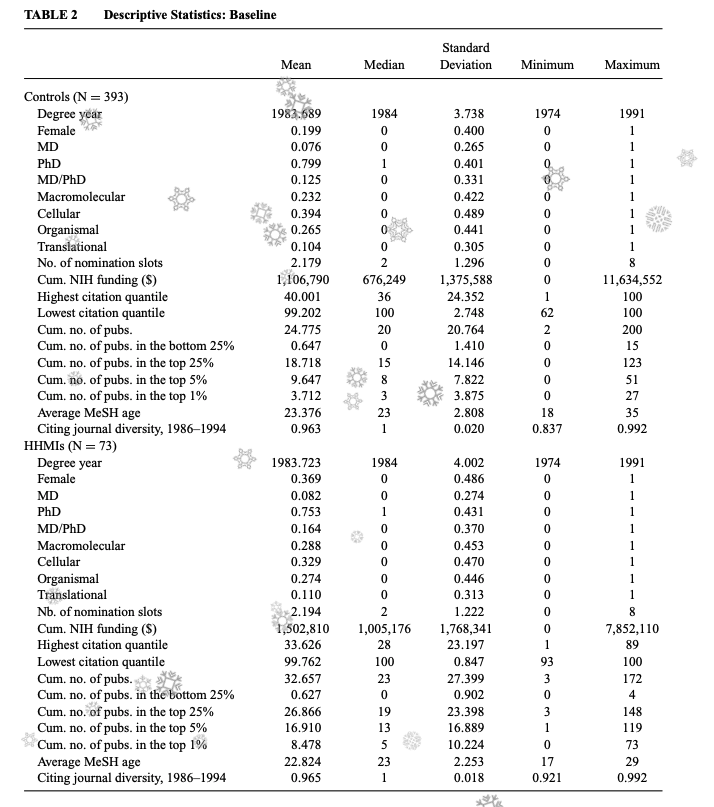
how well can you tell me who became an HHMI researcher vs not? I think, not very well! You'd at the very least want to read some of their papers, or meet them in person, visit their labs perhaps.
The assumption in effect means that the HHMI is modeled to select as if they are looking at data from that table, and not taking anything else into consideration, like any subjective impression they may get from personally interviewing a given candidate. Azoulay et al. are aware of this and they tried to extract this tacit knowledge out of HHMI administrators,
Through interviews with HHMI senior administrators, we have sought to identify the criteria that increase the odds of appointments, conditional on being nominated. As described earlier, the institute appears focused on making sure that its new investigators have stepped out of the shadow cast by their graduate school or postdoctoral mentors. They also want to ensure that these investigators have the leadership and managerial skills required to run a successful laboratory, and interpret receipt of NIH funding as an important signal of possessing these skills. In practice, we capture the “stepping out” criteria by counting the number of last-authored, high-impact contributions the scientist has made since the beginning of his/her independent career.15 We proxy PI leadership skills with a measure of cumulative R01 NIH funding at baseline. Of course, our selection equation also includes important demographic characteristics, such as gender, laboratory type, degree, and career age. [...]
one might worry that the appointment committee is able to recognize and select for “exploratory tendencies” before they manifest themselves in the researcher’s published work. If this were the case, these latent explorers might have branched out in new directions even in the absence of their HHMI appointment. Although we cannot rule out this possibility, we take solace in the fact that ECPW scholars and HHMI investigators are very well matched at baseline along the dimensions of topic novelty and citation breadth, dimensions that we argue are good proxies for exploration. Furthermore, ECPW scholars are selected through a very similar process at an earlier career stage; given that the same individuals, or at least the same type of individuals, often serve on these panels, it is unlikely that the HHMI committee is more skilled at identifying those scientists that are “itching to branch out.”
This strikes me as insufficient to capture what the NIH (Or more broadly, Weaver at Rockefeller, Braben at Research Ventures, and plausibly the HHMI) is doing. Absent an RCT and given that the HHMI does not have rigid rules that would make the process, the inputs and outputs of their selection process perfectly observable, Azoulay et al.'s method may be almost as good as we can get. We could do better for example a) Using an ML model or b) Including more features, for example by text-mining the applicants publication record. Azoulay et al.'s model (Table 5) explains only 16% of the variance in a poisson regression with the outcomes selected/not selected into HHMI, and I bet the remainding is not random. Elsewhere, Azoulay (and Li, 2020) point to earlier work showing that a model to predict future citations works better the lower it is ranked by peers: identifying bad proposals is easy and can be done algorithmically, identifying good ones is harder. It is hence no surprise that they struggle to predict the award decision based on the data they have.
The rest of the paper is actually getting the coefficients for the various effects they measure. Figure 4, below, shows the effect of HHMI appointment. For all publications it does seem believable that HHMI increases output, but not quite for the latter, the rising trend in top articles is there in a way that is not as clear for the other group. Moreover, the top publications for the control group declines which is unexplained in the paper.
An explanation I can think of is by analogy with picking fund managers. Suppose in year Y you look at the top performing 100 funds in the past Y-5 years. Secretly, someone has a list of the minority of "actually good" fund managers who will continue to post high returns. Ex-ante the "actually good" and the "lucky" samples will look the same because the lucky sample has been constructed in a backwards-looking way. But after the selection has been made, the lucky ones will revert to the mean whereas the "actually good" ones will continue their upward trend. The control group may look, swim, and quack like HHMI Investigator material but they may be far from it.
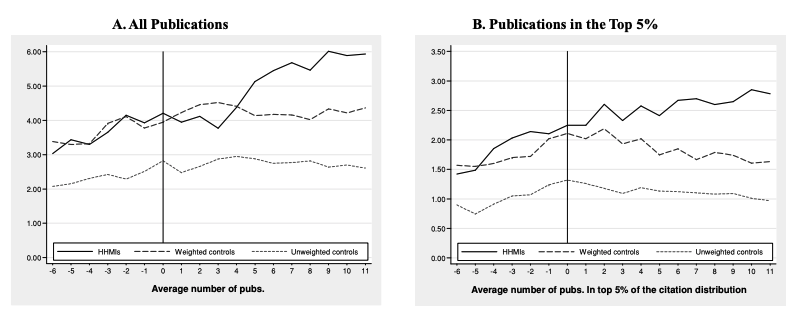
The paper uses various estimates of the effects of interest (Table 6) and as expected the naive (unadjusted) effect goes down when weighing the control sample. The headling "they now publish 97% more top 1% articles" comes from their "SDD" (Semiparametric differences-in-differences estimate which they admit is more prone to bias from pre-existing trends relative to their "DD" (Differences-in-differences) estimate; on this lature the figure is still a non-trivial 43%.
When estimating if HHMIs "fail" more often, we again see the same identification issue:
We find robust statistical evidence that HHMI appointment increases the frequency of both hits and flops. We focus on the latter result, because an increased rate of failure under an exploration incentive scheme is a strong prediction of the theory. It is also more challenging to reconcile with the view that HHMI simply picks extraordinarily talented scientists and then takes credit for their accomplishments. Of course, we cannot rule out a more nuanced selection story whereby the elite scientists who serve as judges in HHMI competitions are skilled at identifying scientists destined to push the scientific frontier outward.
For keyword age (Is HHMI's research more novel?) their Table 8 looks less clear to me, the more robust (But lower powered) DD specification does not achieve significance, and even when the others do, the effects seem small, of about 0.027 years which is negligible.
Later on, when commenting on a potential explanation of their findings, they say:
A more subtle reinterpretation of our main results is that “explorer types” are more likely to seek HHMI appointment. A sorting process in this vein would imply that the freedom and longterm funding bundled with HHMI appointment have real effects, even if they do not really induce behavioral changes in the treated group. However, a peculiar feature of the HHMI appointment process is that candidates do not apply but rather are nominated by their universities, which are endowed by HHMI with a very limited number of nomination slots. This casts doubt on the sorting interpretation at the principal investigator level. It is altogether more likely (and also more feasible) for talented postdoctoral researchers and graduate students with idiosyncratic tastes for exploration to sort themselves into HHMI-funded labs. The fact that HHMI labs train a much higher number of young scientists who go on to win early career prizes is consistent with a sorting process at the level of trainees.
However, it has to be said that this is not true anymore. HHMIs are now self-selected. This does not disqualify their findings (As the HHMIs they examined were indeed nominated by their universities), but the fact that if universities know what HHMI likes, then they will nominate those creative types anyway. So the sorting interpretation cannot be as readily discarded as they authors make it seem.
So does the paper live up to its promise of 96% more high impact citations? I don't think so. To be sure, the data is compatible with that, and Azoulay et al. did a good job given their dataset, but I think it's not enough to warrant strong conclusions about the HHMI. The paper does show at the very least and beyond all doubt that HHMIs are more accomplished than the controls, and that the HHMI can pick out these individuals but whether this is because of the HHMIs being better to begin with or because of the additional freedom afforded by the award is less clear.
NIH Pioneers
But the Azoulay paper is not the only one looking at the effects of funding more, for longer, or with more freedom. As I mentioned before, the NIH has their own HHMI-style programs. There are a number of evaluations of the NIH Director's Pioneer Award, and here I focus on the last of them, for years 2004-2006, covering 35 Pioneers (Summarised in these slides). As with the Azoulay paper, the comparison group for the Pioneers was a matched group drawn from the broader set of R01 grantees in the same periods, as well as a set of HHMI investigators, finalists to the Pioneer award, and lastly randomly selected new grants. This is a rich set of control groups, especially the finalists to the award which should be very close to the researchers that actually got the award; furthermore that paper also studies how much "impact" per $ does the Pioneer award produce. The award is expensive per investigator, so one might argue that it's better to fund more scientists at a lower amount than that giving Pioneer-level money to a few; answering this question is thus interesting.
To measure impact, beside the usual citation metrics, 94 experts reviewed a total of 1923 highly cited papers produced by the various sets of researchers in the study (Each researcher was asked to point to their best work; where they provided less than five they used some heuristics to pick papers until they had five from each), and quantitatively rated each paper on how impactful or innovative it was.
Considering the various metrics holistically, Pioneers~HHMIs>Pioneer finalists>matched R01s>randomly chosen R01s.
Now, some differences between each group:
- HHMIs are markedly younger than the rest
- Pioneers, matched R01s, HHMIs, and Pioneer finalists are largely in top institutions whereas the random portfolio of R01s is mostly not.
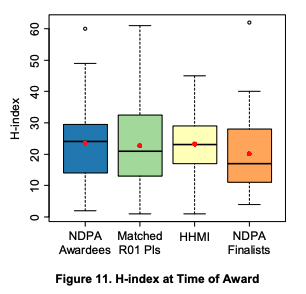
- Pioneers, matched R01s and HHMIs have a similar number of citations pre-award, whereas Pioneer finalists have a lower number (by a small margin) than the rest. The same is true for their h-index.
The fact that Pioneer finalists are not that completely similar to Pioneers makes drawing conclusions harder: If there were a large pool of scientists so skilled it's impossible to rank them in an obvious way, the selection committee would effectively be drawing at random and so we would see that Pioneers and finalists are roughly the same kind of people. But to the extent that applicants can be ranked, then their choice won't be random and we'll observe differences.
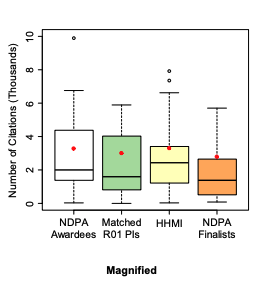
After the award
Pioneers published more, but when accounting for the amount of the grant, they did not
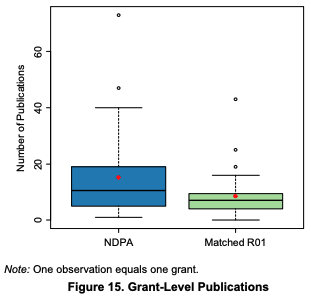
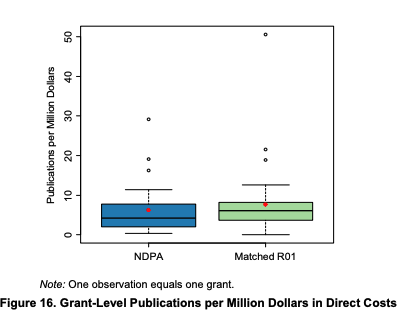
A similar picture is observed for citations: Whereas the study says there was no difference, there clearly was for the right tail: While the median of publication was the same for both groups, the average - driven by extremely cited papers- was substantially higher for Pioneers.
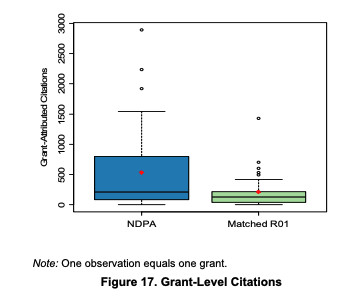
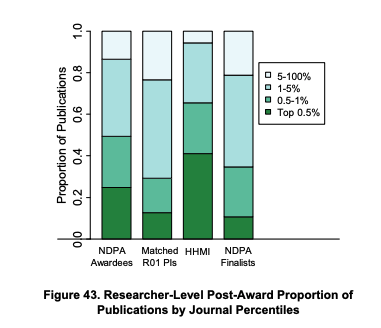
The Pioneers' publications took longer to publish, but once they did they got citations somewhat faster. As a result of producing more publications and more highly cited publications, it's no surprise that Pioneers ended up with a higher h-index as well. The journals where Pioneers published tended to include more higher impact factors, 50% of publications in the top 1% of journals vs 30% for the R01-matched group.
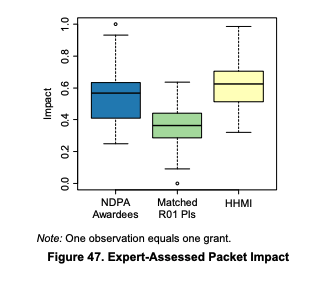
Experts rated Pioneer's grants more highly as well, with the upper quartile of the matches R01s being similar to the lower quartile of the Pioneers(!). The same is true for their assessment of the innovativeness of their work. HHMIs' work was judged somewhat more impactful and innovative3 than that of the Pioneers.
The Pioneers in the aggregate published fewer than 300 publications. Had that money been spent in a portfolio of random R01s, how many publications could have been achieved? (An average R01 is almost half of the Pioneer award) About twice. The portfolio-level analysis looks instead at the sum over all the grants given in each group vs 30 randomly drawn R01s portfolios that cost the same as the Pioneer award portfolio.
The cost of the Pioneer award was not enough to compensate for the large volume of R01s one could have given, and so as a result the sum of citations for Pioneer-authored publications ends up being lower than that of most random R01 portfolios and that of the matched R01s.
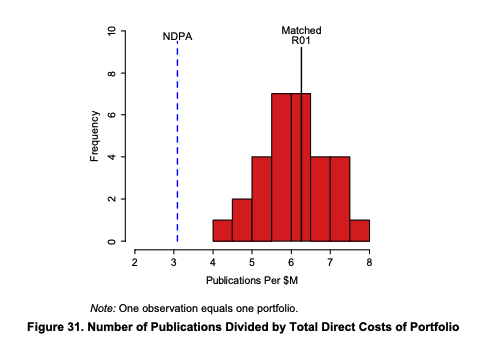
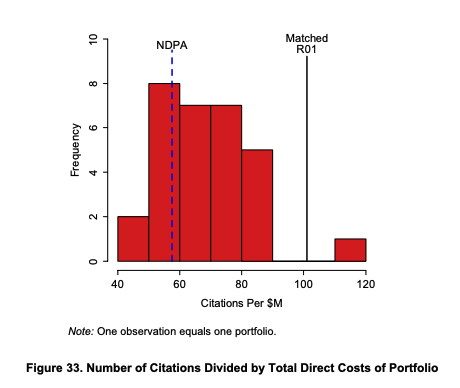
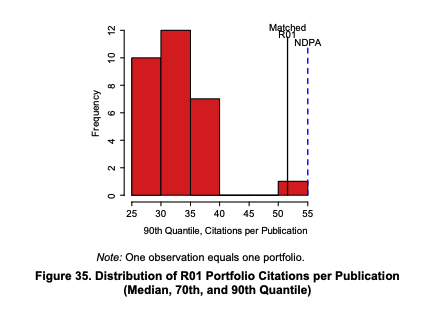
There are lots of figures in this section but the overall picture is that Pioneer award is less efficient at producing citations per $ in total. When one considers the 90th quantile, here we see that the most cited work from the Pioneers (And matched R01 grants) does get more citations than the random portfolios (Note that I'm keping the original figure's footnote; but I have only cropped the panel for the 90th quantile). But we don't have figures for the this metric per $.
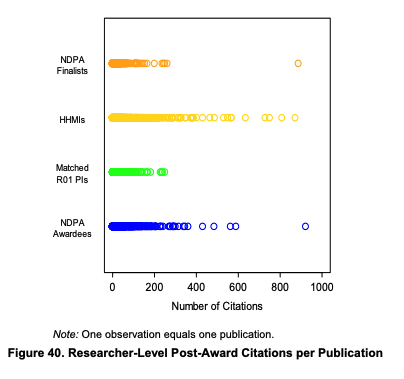
Now, when breaking this down at the publication level and adding also finalists and HHMIs we get a picture coherent with what one might suspect with the figures above, that these "fund people" award winners d end up with a higher count of highly cited publications as well as publishing in higher impact score journals. We said above that finalists were not quite as good as the actual winners of the Pioneer award ex-ante, and this shows up here as well, except for one outlier publication, finalists look like the matched R01s and in turn both are dissimilar from the actual Pioneers and HHMIs (Who seemed to have managed to get even more publications in right right tail). But the differences here, at least subjectively seem greater than at the outset, so again the study is compatible with the award actually having caused those extra high value publications.
Assessing impact and innovation
The use of expert reviewers is a welcome addition to the paper. Citations can be objectively measured but they can leave out a lot of what makes a paper good; conversely expert assessments are necessarily subjective but can provide a richer view of what makes a paper good. Something that stands out from this section as a key difference between each group is that HHMIs were rated similar to Pioneers in doing research that "elucidated new pathways or mechanisms" but HHMIs did markedly less "translational and clinically relevant research". Conversely HHMIs were rated higher in using "research that requires the use of equipment or techniques that have not been proven or considered difficult". So whereas HHMIs and Pioneers are both doing great research, it seems HHMIs are doing more foundational work, perhaps building tools to aid work in other areas. Here I have to add a purely anecdotical comment, that someone told me about a HHMI investigator that ended up quitting, in that case it seems HHMI tried to push this person to use newer and fancier tools than he deemed necessary for his research. So maybe HHMI has a strong prior that tooling is of the utmost importance and tries to influence researchers in that direction, which would show up in what the investigators end up doing.
One key difference between HHMIs and Pioneers is that HHMIs can usually expect to have funding for over a decade (The first review is usually soft) whereas Pioneers are funded for up to 5 years and given less funding. Maybe there are decreasing marginal returns to the "more money and more time" approach but it would be interesting to see what happens if NIH funded a 20-year long long term guaranteed award at HHMI rates of funding for a select few.
Does the Pioneer award "work"?
In the conclusion of the report, their answer is yes. By work this means that they increased the amount of impactful science relative to what the closest controls (Pioneer finalists and matches R01s) would have achieved. Here we face the same issue as with the Azoulay paper in that it's not a properly randomized sample. The addition of the finalist sample to some extent ameliorates this, but even this sample doesn't seem to be sufficiently close to the award winners to consider them a true control.
There is an earlier report that includes fragments of interviews with the Pioneers asking them, for example, if what they planned to research actually changed it to something else or if they followed through with it. A third (7/21) changed. Or, how many Pioneers thought their research project had failed? Again around a third (6/21). It's important that there are at least some; otherwise maybe the research they are doing is not risky enough!
This report also discusses what happened to those that applied to the award that did not get it. Did they end up doing their research anyway? The answer is... actually yes, 80% of them did at least partially and 24% of them completely pursued what they wanted to do for the Pioneer award. They did this by a combination of just using other grants or just working unfunded. The Pioneer award explicitly seeks to fund research that would not have been funded otherwise and so one finds that the award reviewers thought some people and proposals were brilliant but that would probably get funding anyway:
Excellent investigator and quite good problem but not obviously suited for, or requiring, NDPA mechanism of funding
―The candidate is outstanding and the ideas seem quite good. However, it doesn't seem to be much of a departure from what [s/he] is currently pursuing…
This is a very excellent PI and the questions that [s/he] raises have great intrinsic interest and health relevance. However, this is an area [s/he] has long worked in and in fact has an NIH R01 grant pending
Hence it's no surprise that finalists got funded anyway, even if their ideas were good. NIH is then looking for just good ideas or even really good ideas, but ideas such that it's unlikely someone else will fund them. Maybe the finalists are great as scientists but are proposing conservative research projects. Measuring the quality of these research projects ex-ante was not included in the models (here or in Azoulay's paper), so it could be that a lot of signal is hidden there.
Other "People, not projects" grants
You know who doesn't have to apply for grants and have their salaries fully covered for life? NIH intramural researchers! Albeit a small portion (10%) of NIH funding, they exist and their uniqueness should be leveraged to measure the impact of differences in time horizons in various research metrics. If more funding stability is better, and assessing the investigator's whole undirected research output rather than specific papers is also better what's the effect of funding for life coupled with a "fund people" approach? There are, to be sure, confounding factors, as Azoulay (2015) points out, critics inside and outside the agency argued that its quality had slowly deteriorated. In particular, they pointed out that the rigidity in pay scales and promotion policies (intramural scientists were federal employees) made it extremely difficult to hire or retain top investigators
Some things I found: Poulin & Gordon (2001) put the intramural NIH researchers on the same footing as Bell (Labs) in how good they are at "inspiring innovation". Accordingly their program (1200 PIs right now) has produced or train 21 Nobel Prize winners (That's 250 investigators, and 32 Nobel Prizes for HHMI as a comparison). 163 NIH-funded researchers have won Nobel Prizes (Counting intramurals), and there are perhaps 300k researchers. That would be 17.5 milliNobels for Intramurals, 128 milliNobels for HHMI and 0.54 milliNobels for the NIH at large. Even when counting just Nobels won by Intramurals (six), that's still 5 milliNobels, or 10x more than NIH in general. Still falling short of the HHMI but not bad! (The right way of doing this exercise would use the total historical number of supported investigators at each programme; here I am assuming the cohort sizes have always been the same, which is probably not true. But the orders of magnitude may still be if cohort sizes have changed in similar ways in the case of NIH extramural and intramural programs; for HHMI the numbers may be more skewed as there are fewers investigators than intramural researchers).
But ultimately if we want something more solid than this, we have to agree with I tried with Azoulay who already thought of this group of researchers:
To our knowledge, there is no empirical evidence to date that can speak to the relative merits of “extramural” funding through a decentralized, investigator-initiated process versus “intramural” funding filtered through a decision-making hierarchy (Azoulay & Li, 2020)
The same is true for the Investigator Awards in Science at the Wellcome Trust in the UK (Though unlike HHMI these don't cover salary), there isn't much known on its effectiveness. We know that this program was a shift in Wellcome's policy (previously they funded more project grants) and that the justification is not any formal research but what also seems to be justification for the HHMI and NIH Director's Pioneer award: That science is disproportionately advanced by a small elite of giants building on top of each other (The Newton hypothesis), rather than built on top of the shoulders of vertically challenged men (The Ortega hypothesis). This is a different question that can be more easily studied than the effects of these prestigious awards in specific. That will be a matter for another blogpost.
Canada represents an interesting example in that they used to allocate a lot of funding along "people" lines but they recently decided to sunset their 7-year Foundation Grant on what to me seem to be bad reasons (inequity in allocating the grants by gender, research area, or institution). Analysis on wether this grant led to more impactful science or not seems completely absent! Likewise this paper that calls for "funding projects, not people" makes no reference to scientific outcomes. Equity doesn't necessarily imply excellence, and when they are at odds, pursuing equity may come at the cost of the science.
Foundation Grants were a sizable chunk (100M$ per year out of 600M$) of the Canadian Institutes of Health Research's budget, and were instituted around a decade ago. If the data could be compiled, maybe the pre, during, and post Foundation eras could be used to measure their effectiveness.
Conclusion
Ultimately it's hard to disagree with Azoulay & Li (2020), we need a better science of science! The scientific method needs to examine the social practice of science as well, and this should involve funders doing more experiments to see what works. Rather than doing whatever is it that they are doing now, funders should introduce an element of explicit randomization into their process.
Is funding people better than funding projects? The two studies reviewed here do not answer this question; rather they give evidence for two specific programs that aim as well to fund highly talented researchers. We can't draw strong conclusions from these studies and so whether we think they worked or not will depend on our priors about these approaches. To better inform them we would need to answer these questions first:
- To what extent is science driven by a small minority vs a collective achievement? (The more important nurturing the elite is, the more sense it makes to make targeted investments)
- Given that Pioneers were not obviously inferior to HHMIs in outcomes, and yet their funding has a hard limit of 5 years (7 at least but really 15 on average in HHMI's case), is HHMI being too generous? Or is their kind of support required to produce more of the very top of the publications?
- What would be the consequences of equalising funding access so that every scientist get a similar share?
- To what extent the Matthew effect operates in science? (That is, is the distribution of scientific success skewed due to current winners winning more grants and awards?)
- Can winners be picked? Does pre-award peer review work? (If winners cannot be picked, then what HHMI and the Pioneer award are doing is pointless; intuitively it does seem that at least in some context and to some degree they can be picked)
- What is the ideal composition of funding for science in general? (Should most science be funded via lotteries, with a small portion of competitive long-lasting grants?)
I hope to answer some of these in future posts.
Citation
In academic work, please cite this essay as:
Ricón, José Luis, “Fund people, not projects I: The HHMI and the NIH Director's Pioneer Award”, Nintil (2020-12-27), available at https://nintil.com/hhmi-and-nih/.
Backlinks
- Fund people, not projects IV: Scientific egalitarianism and lotteries
- Fund people, not projects II: Does pre-grant peer review work?
- Limits and Possibilities of Metascience
- New Science's NIH report: highlights
- Fund people, not projects III: The Newton hypothesis; Is science done by a small elite?
- Notes on 2021
- Evidence and the design and reform of scientific institutions
- Fund People, not Projects V: Fund for longer?
Comments