The Entreprenerial State: El caso de Google
Otro Mazzucatismo es el caso de Google. En The Entrepreneurial State, Mazzucato habla de Google en varias ocasiones:
Yet in many countries, they receive more support than the police force, without providing the jobs or innovation that helps justify such support (Hughes 2008; Storey 2006). Had the State better understood how its own investments have led to the emergence of the most successful new companies, like Google, Apple and Compaq, it would perhaps mount a stronger defence against such arguments. [...] The emphasis on the State as an entrepreneurial agent is not of course meant to deny the existence of private sector entrepreneurial activity, from the role of young new companies in providing the dynamism behind new sectors (e.g. Google), to the important source of funding from private sources like venture capital. The key problem is that this is the only story that is usually told. Silicon Valley and the emergence of the biotech industry are usually attributed to the geniuses behind the small high-tech firms like Facebook, or the plethora of small biotech companies in Boston (US) or Cambridge (UK). Europe’s ‘lag’ behind the USA is often attributed to its weak venture capital sector. Examples from these high-tech sectors in the USA are often used to argue why we need less State and more market: tipping the balance in favour of the market would allow Europe to produce its own ‘Googles’. But how many people know that the algorithm that led to Google’s success was funded by a public sector National Science Foundation grant (Battelle 2005)? [...] There is indeed lots of talk of partnership between the government and private sector, yet while the efforts are collective, the returns remain private. Is it right that the National Science Foundation did not reap any financial return from funding the grant that produced the algorithm that led to Google’s search engine (Block 2011, 23)? [...] After Google made billions in profits, shouldn’t a small percentage have gone back to fund the public agency that funded its algorithm?
Las fuentes que se citan son dos:
- Battelle, J. 2005. The Search. New York: Penguin.
- Block, F. L. Innovation and the Invisible Hand of Government. In State of Innovation: The U.S. Government’s Role in Technology Development, edited by F. L. Block and M. R. Keller. Boulder, CO: Paradigm Publishers.
Se afirma lo siguiente:
- Ciertas inversiones estatales han dado lugar a la mayoría de nuevas compañías exitosas
- El algoritmo que llevó a Google al éxito fue financiado por la National Science Foundation
- Se plantea que el Estado debería recibir parte de los beneficios de Google, en tanto financió etapas iniciales del desarrollo del algoritmo.
- Google sería imposible sin el Estado (No en el libro, pero sí en otro sitio)
¿Qué se dice en el libro de Battelle sobre la NSF y Google? Las palabras "NSF" y "National Science Foundation" no aparecen en todo el libro. Sí podemos encontrar lo siguiente:
- Google no fue el primer buscador. Antes estuvieron Archie y Gopher
- La búsqueda de información y su indización han preocupado al ser humano desde los orígenes del lenguaje simbólico, y especialmente, desde la invención de la imprenta.
- El que se considera el primer motor de búsqueda digital (pero no de internet), SMART, fue desarrollado por Gerard Salton, un matemático de las universidades de Harvard y Cornell. Tras su trabajo comenzó una serie de conferencias (TREC) sobre el tema de la búsqueda de datos. Sin embargo, no se centraban en la web al considerarla demasiado caótica para indizarla bien.
- El primer motor de búsqueda de internet fue Archie, una aplicación de búsqueda anterior a la web creada en 1990 por un estudiante de la McGill University, Alan Emtage. Archie buscaba archivos en internet y los indizaba. Estaba orientado a búsqueda de artículos académicos, y no tuvo mucho uso más allá de techies y académicos.
- En 1993 aparece Veronica, creado por estudiantes de la Universidad de Nevada, que funcionaba como Archie, con alguna modificación. En ambos casos, sólo permitían buscar por título del artículo.
- Con el crecimiento de la red, se hace difícil encontrar lo que se busca, y en 1993 nace WWW Wanderer (Matthew Grey, un investigador del MIT). Wanderer creaba un índice de la web que permitía luego buscar en ese índice.
- Luego vino WebCrawler (Brian Pinkerton, Universidad de Washinton, que lo diseñó mientras trabajaba en la empresa de Steve Jobs 'Next', donde también se desarrolló Ethernet y sistemas de presentación de color de alta calidad, tecnologías comunes hoy. Pinkerton tenía la tarea de diseñar un navegador web con capacidad de búsquedas para el sistema NextStep, y su solución fue parecida a la que luego usara el algoritmo PageRank de Google: tratar de calcular la popularidad de un sitio a partir de las páginas que enlazan a ese sitio. WebCrawler fue adquirido por AOL por 1 millón de $
- Se dice que Xerox PARC inventó el ordenador personal y las interfaces gráficas (Alguien podría, al estilo Mazzucato, escribir un libro loando los laboratorios PARC ("De no ser por PARC no tendríamos el ordenador...") y exigiendo que todo usuario de un portátil, smartphone o tablet, en tanto tienen interfaces gráficas, les paguen royalties. Tan absurdo es esto como el planteamiento general del libro de Mazzucato)
- En 1994-95, había unos 12 motores de búsqueda, pero todos tenían ciertas deficiencias. Con un ordenador bastante potente, Alpha, Louis Monier de DEC desarrolla la idea de crawler, un programa que va página a página indexándola, siguiendo sus enlaces de forma sistemática, de forma que al final se logra un atlas completo de toda la red. Esta fue la base del buscador AltaVista, descrito en el libro como el Google de su tiempo.
- DEC hacía bastante dinero en 1990 vendiendo miniordenadores VAX a empresas, ganando unos 14 billones de dólares en ingresos. En el 95, perdía 2 billones al año. Se había sobreexpandido para centrarse en miniordenadores y no supo responder ante la creciente demanda de PCs que sí fue respondida por Compaq o Dell. Esta primera compró AltaVista por 9.6 billones de $ en 1998
- Lycos nace en 1994, de la mano de Michael Mauldin, que trabajaba con una beca de DARPA (Defense Advanced Research Projects Agency). Fue el primer motor de búsqueda de cierto uso (porque WebCrawler ya lo hacía) en hacer uso de enlaces para calcular la popularidad de un sitio. Lycos fue comprada por Terra por 12.5 billones de $.
- Excite, nacida con el nombre de Architext en 1994, fue fundada por seis alumnos de Stanford, amigos desde primero de carrera. Su objetivo era crear tecnología de búsqueda para grandes bases de datos dentro de corporaciones, pero uno de los capitalistas de riesgo (venture capitalists) que les financiaba, Vinod Khosla, les conminó a centrarse en el mercado de consumo. Les financió con 1.5 millones de $, más otros 250,000$ de Geoff Yang, otro VC. También tenía un motor de búsqueda propio. Cuando salió a bolsa, logró captar 177 millones de $ en financiación.
- Yahoo empezó a principios de los 90 con dos doctorandos de Stanford que se aburrían en su dormitorio y que se montaron un sistema para ganar en un juego de ordenador que simulaba una liga de béisbol. Por aquel entonces, la WWW era un experimento académico. Desarrollaron un sistema tipo crawler para ello. En el 93, sale Mosaic, el primer navegador, y se dedicaron a buscar páginas que les interesaban y a guardar una lista. En 1995, otros venture capitalists, Sequoia Capital les financia con 2 millones de $.
- Llegamos a Google. Sergei Brin y Larry Page, los fundadores, se conocen en 1995 en Stanford. Page escoge a Terry Winograd como tutor. Winograd era un pionero en sistemas de interacción hombre-máquina. Page se puso a buscar un tema para su tesis, y terminó centrándose en la web. No por que hubiese dinero - otros compañeros de universidad estaban lanzando empresas y haciéndose ricos - sino porque encontraba interesantes ciertas propiedades matemáticas de la web: cada ordenador es un nodo, y cada link es una conexión.. La web es un grafo. El problema que quiso resolver era el siguiente: encontrar, dada una página, las páginas que enlazan a esa. Al revés de lo que se había hecho hasta ahora: encontrar a qué páginas enlaza una dada. Page razonó que la estructura de la web era como la de citas en el contexto académico: unos artículos que enlazan a otros, los artículos más citados tienen más autoridad que los menos citados. Así funcionan los índices de impacto, según se describe en documentos de la época. La idea subyacente a Google, PageRank, es, en principio, una transposición a la web del sistema de impacto de las revistas científicas. Para resolver este problema él y Brin desarrollan BackRub, un programa capaz de indicar qué páginas enlazan a una dada. Inicialmente no querían hacer un motor de búsqueda como tal, pero para programar BackRub tuvieron que diseñar a su vez un crawler, que como vimos es un componente importante de un buscador. Tras un tiempo de uso, vieron que sus resultados eran mejores que los de AltaVista o Excite.
- Google nace en 1996, y empezaron con un ordenador hecho con piezas de otros ordenadores, ordenadores prestados.
- Jon Kleinberg, investigador de IBM que trabajaba en un algoritmo similar a PageRank oye hablar de BackRub y contacta con Page y Brin. Kleinberg les animó a que publicasen su investigación, pero Page dudaba de si hacerlo: alguien podría robar sus ideas. Pero al final, la búsqueda de la fama académica terminó ganando, y en 1998, Page envía para publicación un artículo describiendo los fundamentos de PageRank, pero es rechazado. Vuelve a intentarlo y lo logra publicar junto a un proyecto de la universidad de Stanford, el "Digital Libraries Project"
- En aquel momento, había varias empresas bien financiadas dedicadas a la búsqueda, y Page y Brin razonan que lo mejor sería licenciar su tecnología a una compañía. Temían que si lanzaban una compañía, serían aplastados por los grandes y más ricos competidores. Contactaron con Vinod Khosla, quien medió entre Google y Excite para negociar la compra del primero por algo menos de un millón de dólares, pero las negociaciones no llegaron a término.
- Durante más de un año, demostraron su tecnología a casi todas las empresas de búsqueda del sector y a varios venture capitalists. Todos encontraban la tecnología interesante, pero no estaban dispuestos a apostar por ella. Pero viendo que en su servidor de Stanford el tráfico no dejaba de crecer, se deciden a lanzar su propia empresa. Para ello, contactan con David Cheriton, profesor de Stanford, que les pone en contacto con Andy Bechtolsheim, fundador de Sun Microsystems y que financiaba proyectos que daban sus primero pasos. Aceptó financiarles con 100,000$.
- Google Inc, ya como compañía, aparece el 7 de Septiembre de 1998. En 1999 logran inyecciones de capital de 25 millones de $. Cuando en 2003 salen a bolsa, captan 1.670 millones de $.
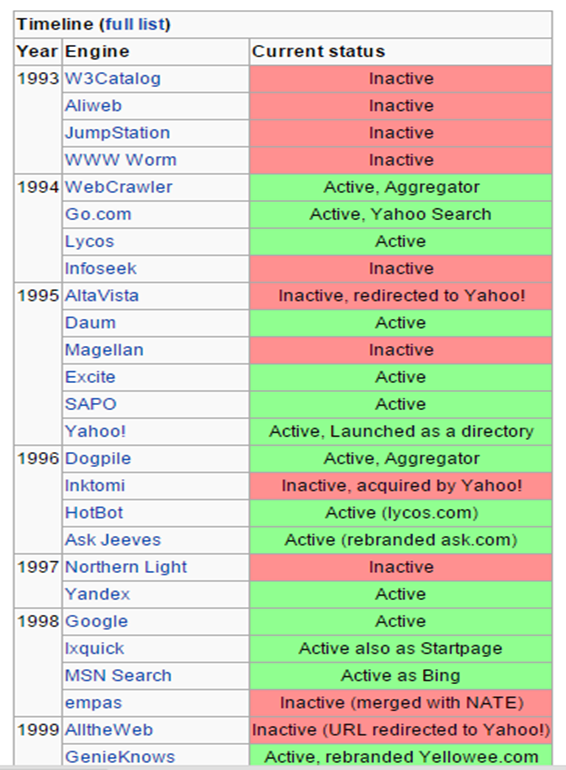
Figura: Buscadores existentes antes de Google
Uno lee esto y saca la conclusión de que Google es fruto de la pasión de dos jóvenes estudantes, de las conexiones que tuvieron a través de su universidad, y de la financiación de los venture capitalists. El libro es totalmente anti-Mazzucatiano. Pero para ser justos con Mazzucato, en el libro hay una cosa que, si bien se menciona muy de pasada es el hilo del que vamos a tirar para sacar dónde estuvo la intervención estatal en todo esto. Se trata del "Digital Libraries Project". ¿Qué tendría que haber hecho Mazzucato para decir lo que dice? Irse a la página de la NSF donde dicen que
In the primordial ooze of Internet content several hundred million seconds ago (1993), fewer than 100 Web sites inhabited the planet. Early clans of information seekers hunted for data among the far larger populations of text-only Gopher sites and FTP file-sharing servers. This was the world in the years before Google. Even in this primitive Internet world, the need for more accessible interfaces to growing data collections had already been recognized. The National Science Foundation led the multi-agency Digital Library Initiative (DLI) that, in 1994, made its first six awards. One of those awards supported a Stanford University project led by professors Hector Garcia-Molina and Terry Winograd. [...] In 1994, some of the first Web search tools crawled out of the Internet sea. Two Stanford students started Yahoo!, a manually constructed "table of contents" for Web sites. Other early search engines emerged, such as Lycos and WebCrawler, and began automatically indexing Web pages, focusing on keyword-based techniques to rank search results. [...] Page was soon joined by Sergey Brin, another Stanford graduate student working on the DLI project. (Brin was supported by an NSF Graduate Student Fellowship.) Together, Page and Brin constructed an ambitious prototype in their Stanford student offices. The equipment for the prototype, called BackRub, was funded by the DLI project and other industrial contributions.
En Politifact analizan esto y citan a Mark Malseed, autor de otro libro sobre Google, donde dice que, sí, que recibieron fondos de la NSF a través del programa DLI, pero que no es muy relevante para el orígen de Google. Ronald Rice, profesor de la Universidad de California, le da más peso a los fondos de NSF, pero no parece muy convincente si uno lee el sitio. En general, la gente brillante a la que le gusta investigar y tiene curiosidad por un tema, va a investigar ese tema si puede. Si además logra que alguien le pague por ello, mejor. Por tanto, es lógico que Brin pidiese una Fellowship a la NSF y que se adscribiesen al programa DLI. Tengamos también en cuenta que DLI nace en 1994. Y hemos visto que los buscadores de internet venían desarrollándose desde al menos 4 años antes. Ideas similares iban surgiendo, y de hecho un algoritmo similar a PageRank fue desarrollado fuera del contexto universitario. La patente de PageRank hace referencia, de hecho, a RankDex, 1996) Retrocedamos a la segunda fuente de Mazzucato: Innovation and the Invisible Hand of Government de Fred Block. Ahí se dice que
The algorithm or “secret sauce” that made Google so successful as a search engine was initially funded by an NSF grant (Battelle 2005), but the only benefit that NSF received was the indirect one that Google’s growth and large payroll expanded the government tax revenues that help fund NSF and other innovation agencies
Se cita la fuente que ya hemos analizado. El número de personas que no saben leer - O siendo más caritativos, que hacen una interpretación bastante choricera de los hechos - no se limita a Mazzucato. Porque primero, es cierto que fondos de la NSF intervinieron en el orígen de Google. Pero eso no se explica bien en el libro de Battelle. ¿Qué sentido tiene citar un libro que narra una historia de venture capitalists, entusiasmo juvenil, investigadores y competencia empresarial? Sí, en una página dicen de pasada "Digital Libraries Project". Pero no se menciona que eso lo financiase la NSF -que lo fue, el punto no es negarlo-. Por hacerme entender, es como si yo citase el libro de Mazzucato como prueba de (la falaz tesis de) que el mercado es un invento estatal (la tesis de Karl Polanyi, que sale citado en el libro). Sí, en el libro se dice eso, pero de pasada. Si quiero defender esa tesis, debería citar directamente a Polanyi, no a Mazzucato. Si cito a Mazzucato, da la impresión de que no me he querido leer las fuentes originales o de que no he leído bien de qué va el libro que cito.
Luego, como se comenta en la fuente que citan Mazzucato y Block, Google es el producto de muchísimas interacciones. ¿Cuánto dinero hizo Winograd, o los que les dejaron partes usadas de ordenadores para empezar con Google? Que sepamos, cero. ¿Tienen alguna deuda Google con ellos? No, porque en su momento acordaron que así fuese. Distinto es el caso de Bechtolsheim. Invirtió 100,000$ y ahora tiene 1,700 millones de $. Si Mazzucato y compañía quieren que la NSF u otros laboratorios estatales ganen dinero con lo que venden, tendrían que invertir y asumir riesgos. Será rentable, o no. Una beca o un programa de investigación no es invertir en empresas. ¿Qué queda de este Mazzucatismo? Poco. Aquí, tenemos una industria que había ido madurando antes de la intervención estatal, que genera una empresa exitosa a partir de una cadena de serendipias, a partir de conocimiento hasta cierto punto previo (El sistema de ranking de revistas científicas y otros buscadores. Las invenciones no aparecen de la nada, son graduales), financiada por diversas fuentes, entre ellas, la NSF.
¿Si no les hubiese financiado no tendríamos Google ni nada parecido? A la vista de lo anterior, mi respuesta es que lo más probable es que no: sí hubiésemos tenido algo parecido a Google. Ya se hablaba de buscadores de internet mucho antes de DLI, así que es maś razonable pensar que este programa surge como reacción para investigar en un campo en auge y no al revés (Que DLI fuese el punto a partir del cual se produce ese auge). Había investigación antes, durante y después de DLI en este campo. El primer paper de Brin y Page cita en gran medida fuentes anteriores a DLI. En la NSF tenemos esta página donde se anuncia el inicio de DLI, y se menciona a Hector Garcia-Molina como investigador líder del proyecto. Uno podría decir que con DLI, el foco de la investigación del equipo de Molina cambia radicalmente para enfocarse en eso. Pero eso no es obvio. Aquí está el primer informe del proyecto DLI. Podemos encontrar citas a WebCrawler y a Lycos, y el creador de WebCrawler, que se doctoró en el año 2000 explica en su tesis las investigaciones que le llevaron a eso. El campo ya tenía bastante desarrollo antes del 94. Alguien podría decir que Lycos también es fruto de DLI, porque efectivamente su fundador participó en 1994 en el programa. Entonces puede uno ir al CV de Mauldin y ver que Lycos se basa en trabajo previo al programa financiado por el programa TIPSTER de DARPA (Ese trabajo previo estuvo también financiado por la Heinz Foundation y otros).
Pero TIPSTER pretendía avanzar desarrollos e investigaciones ya existentes. Los campos que dicen querer investigar ya estaban activos antes de su programa. Alguien podría volver a querer ir atrás y buscar en los orígenes de uno de ellos, como "Information Extraction" y ver que nuevamente encontramos a DARPA, pero aquí otra vez encontramos más trabajos previos (El sistema TACITUS de SRI que si bien participó luego en programas de DARPA (Como parte de otro programa llamado FASTUS), comenzó como un desarrollo interno de SRI, un laboratorio independiente. Pero TACITUS también fue financiado por DARPA, así como DIALOGIC, otro predecesor. Ahora podría ir a la historia de estos sistemas, las bibliografías de sus artículos y repetir el procedimiento aquí esbozado. No sería de extrañar que llegásemos a la conclusión de que DIALOGIC es un desarrollo incremental de un trabajo previo de un investigador que ya estaba (antes de meter a DARPA de por medio) investigando ese campo. En este caso, a Richard Montague, un filósofo. Etc...
Por concluir: Estudiar la historia de la ciencia y la tecnología es la mejor manera de entender cómo funciona la innovación. Y un patrón bastante claro en toda la Historia es que las innovaciones casi casi siempre son graduales, se producen en muchas ocasiones en varios sitios y atribuir la causalidad total de algo a una persona en concreto es extremadamente difícil. Larry Page y Sergei Brin crearon Google, pero no la idea de motor de búsqueda ni de algoritmo basado en popularidad. Son responsables de un paso más en el avance de la técnica. Sin ellos, es razonable pensar que, dada la situación de la época (otros estaban trabajando en cosas muy parecidas) alguien hubiese descubierto algo parecido a PageRank en algún momento u otro.
Las matemáticas y las leyes físicas no varían, antes o después alguien termina descubriendo teoremas y leyes físicas nuevas. Mientras el ser humano sea curioso, seguiremos teniendo ciencia. Más rápido o más despacio, eso es otra cuestión separada a estudiar. Y mientras el ser humano tenga espíritu empresarial, seguiremos teniendo empresas que nos conviertan los últimos avances de la técnica en productos que satisfagan las diversas y variables preferencias humanas.
Citation
In academic work, please cite this essay as:
Ricón, José Luis, “The Entreprenerial State: El caso de Google”, Nintil (2015-02-14), available at https://nintil.com/mazzucatismos-el-caso-de-google/.
Comments